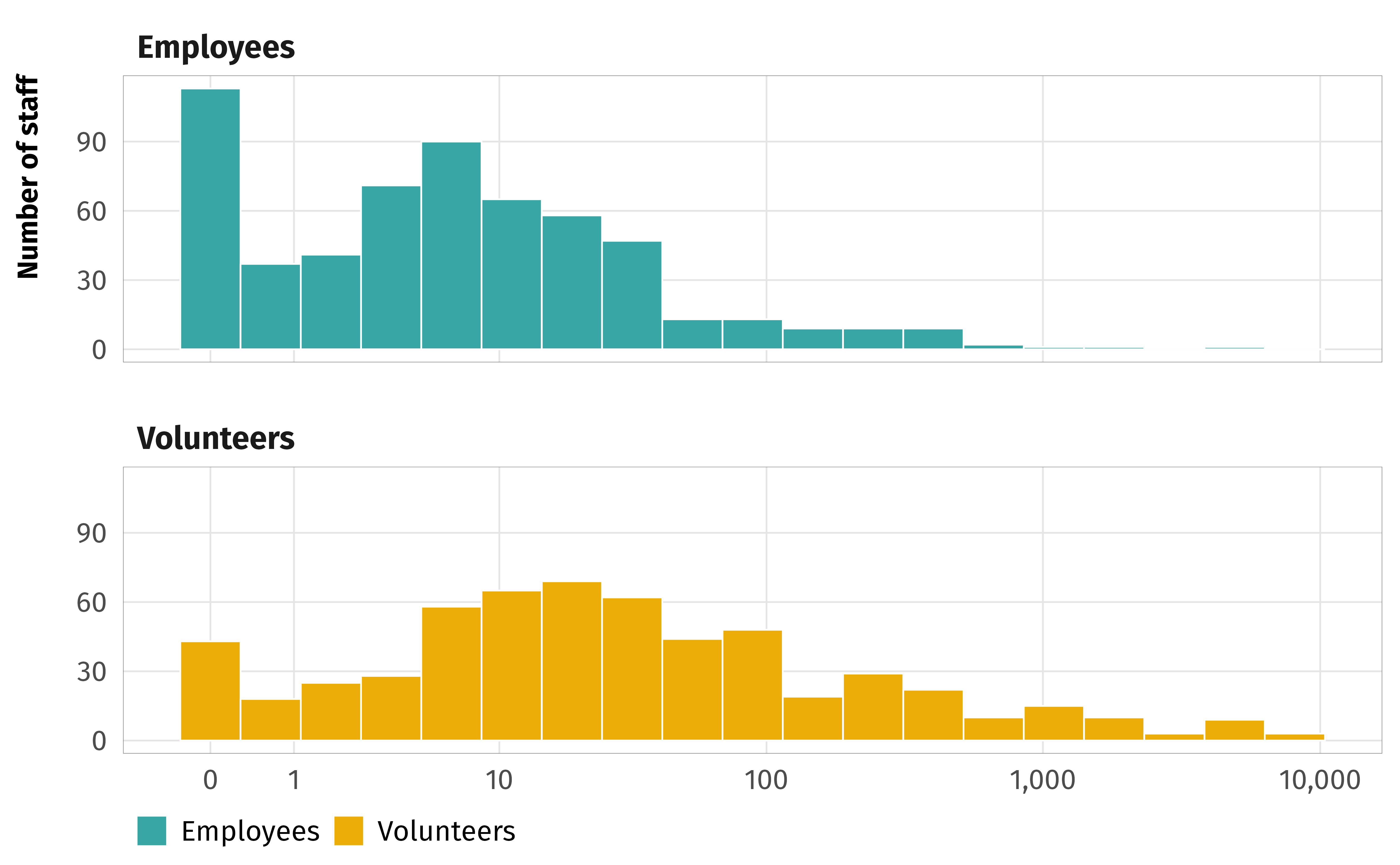
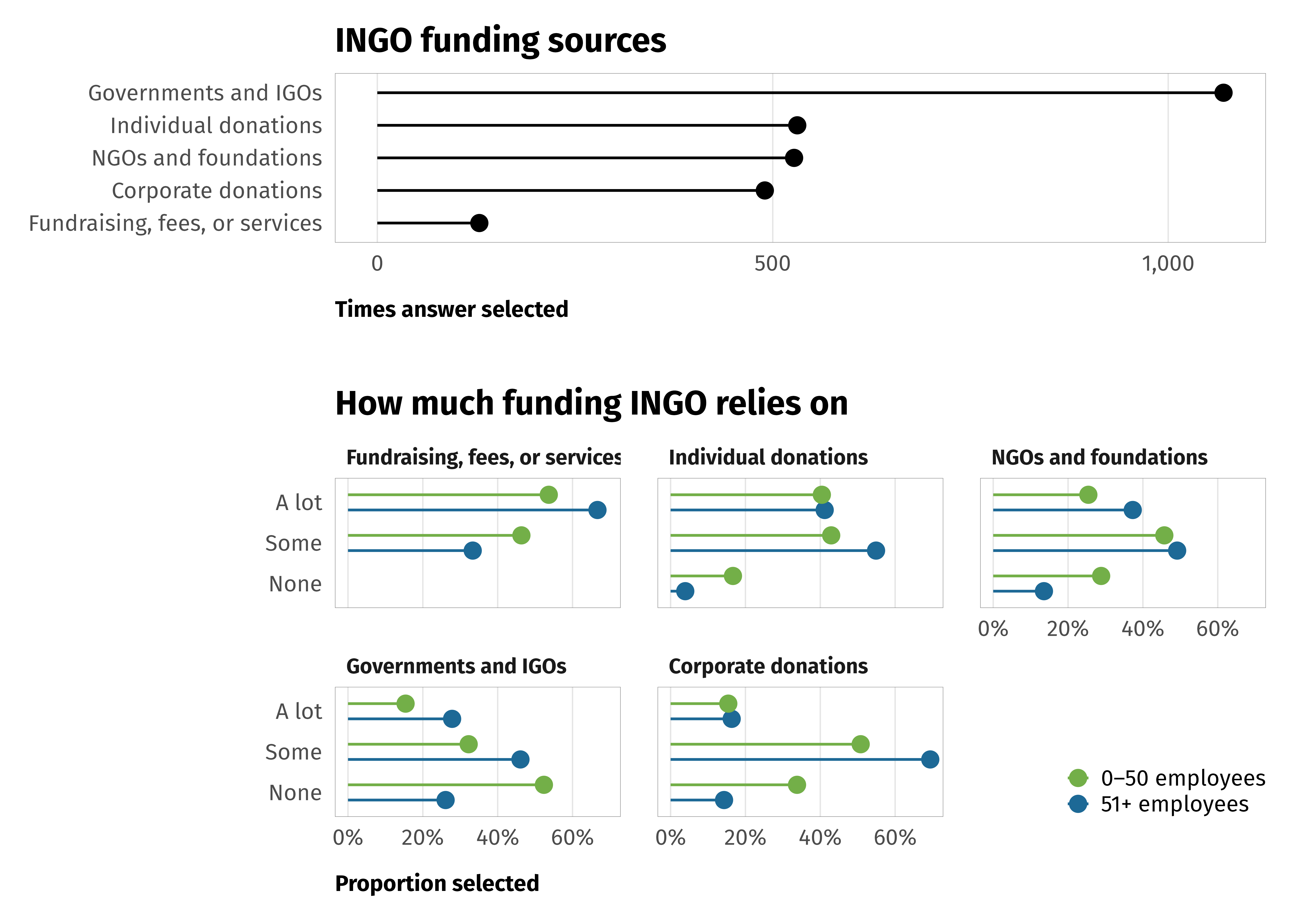
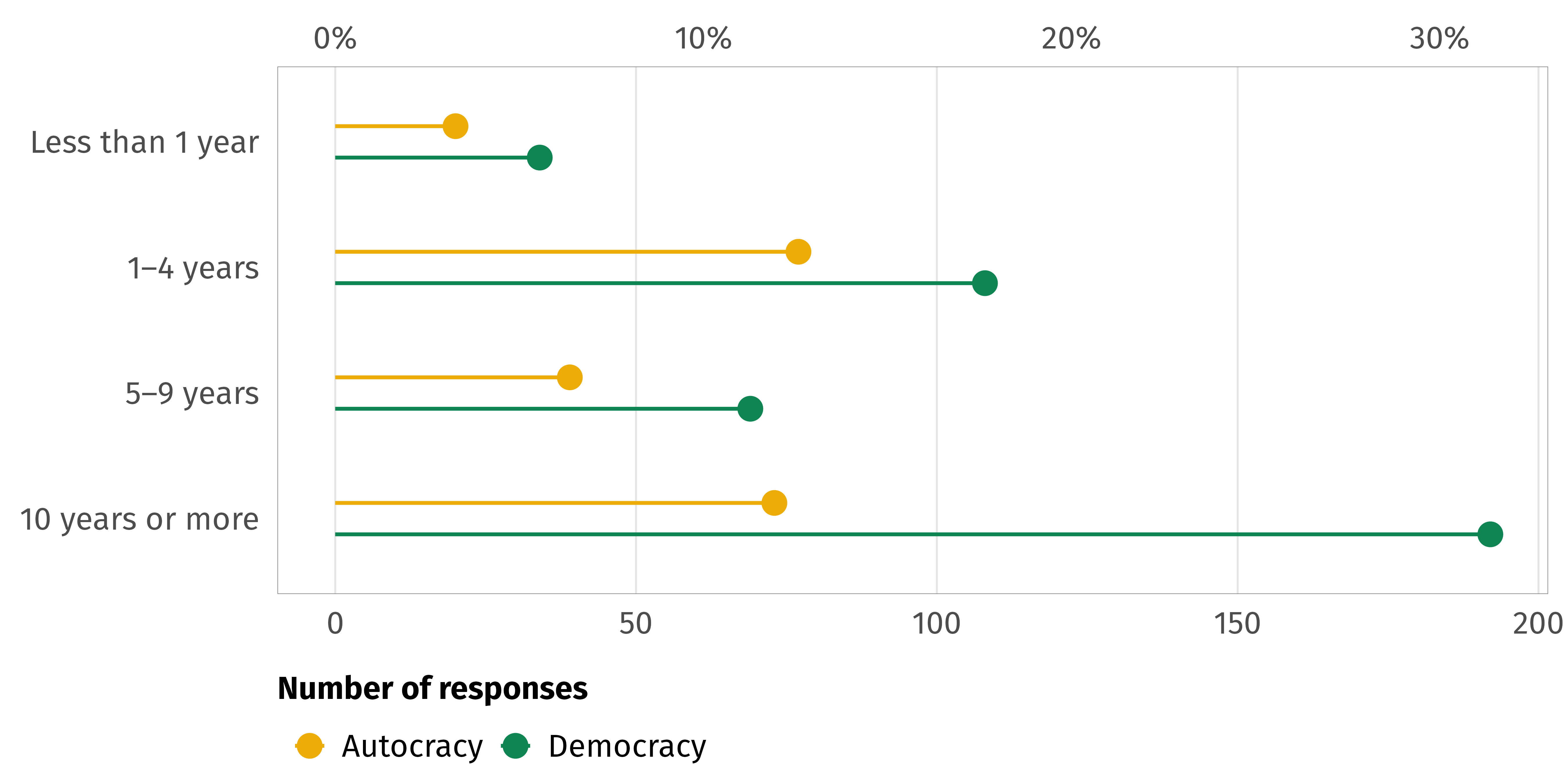
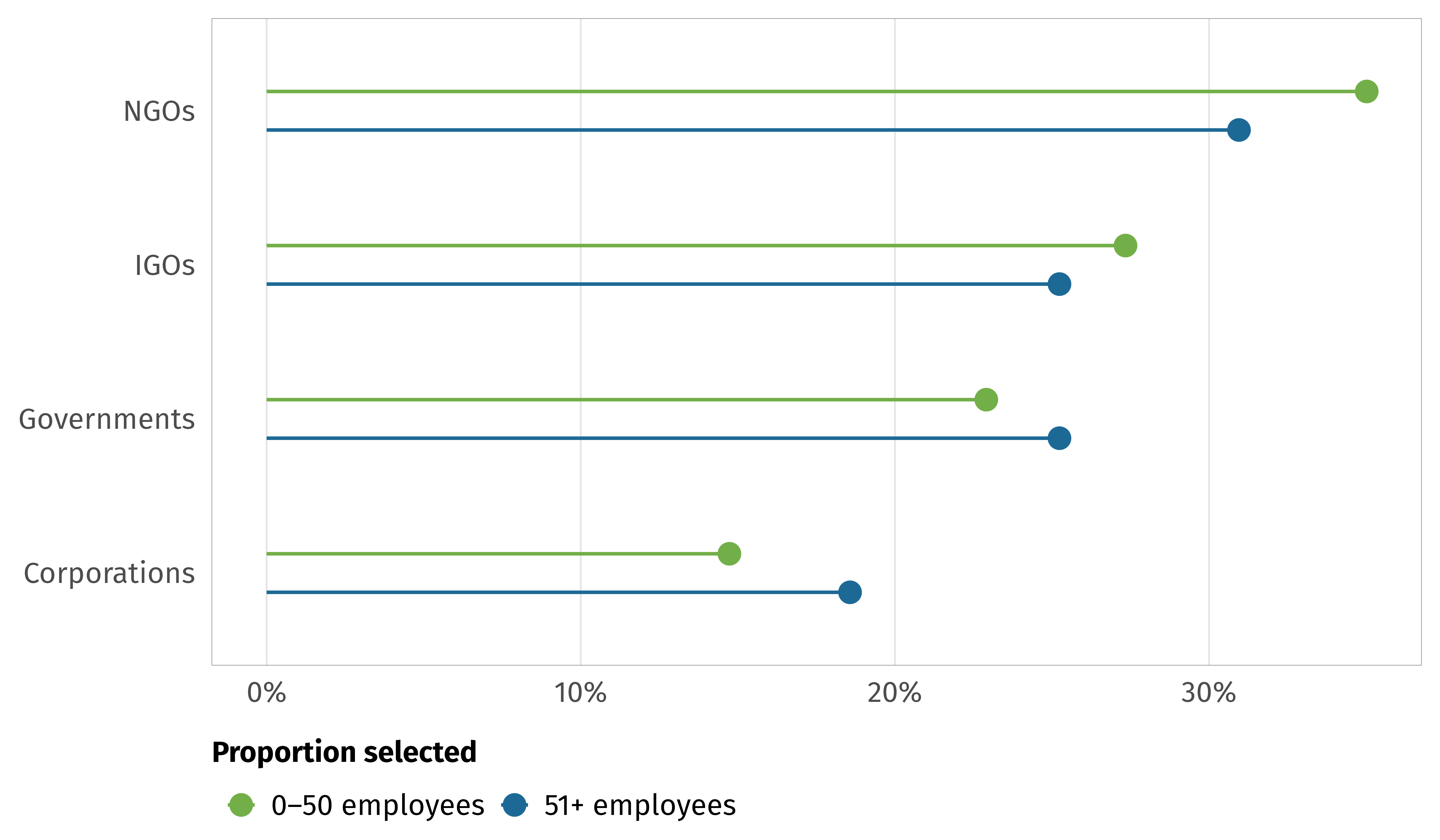
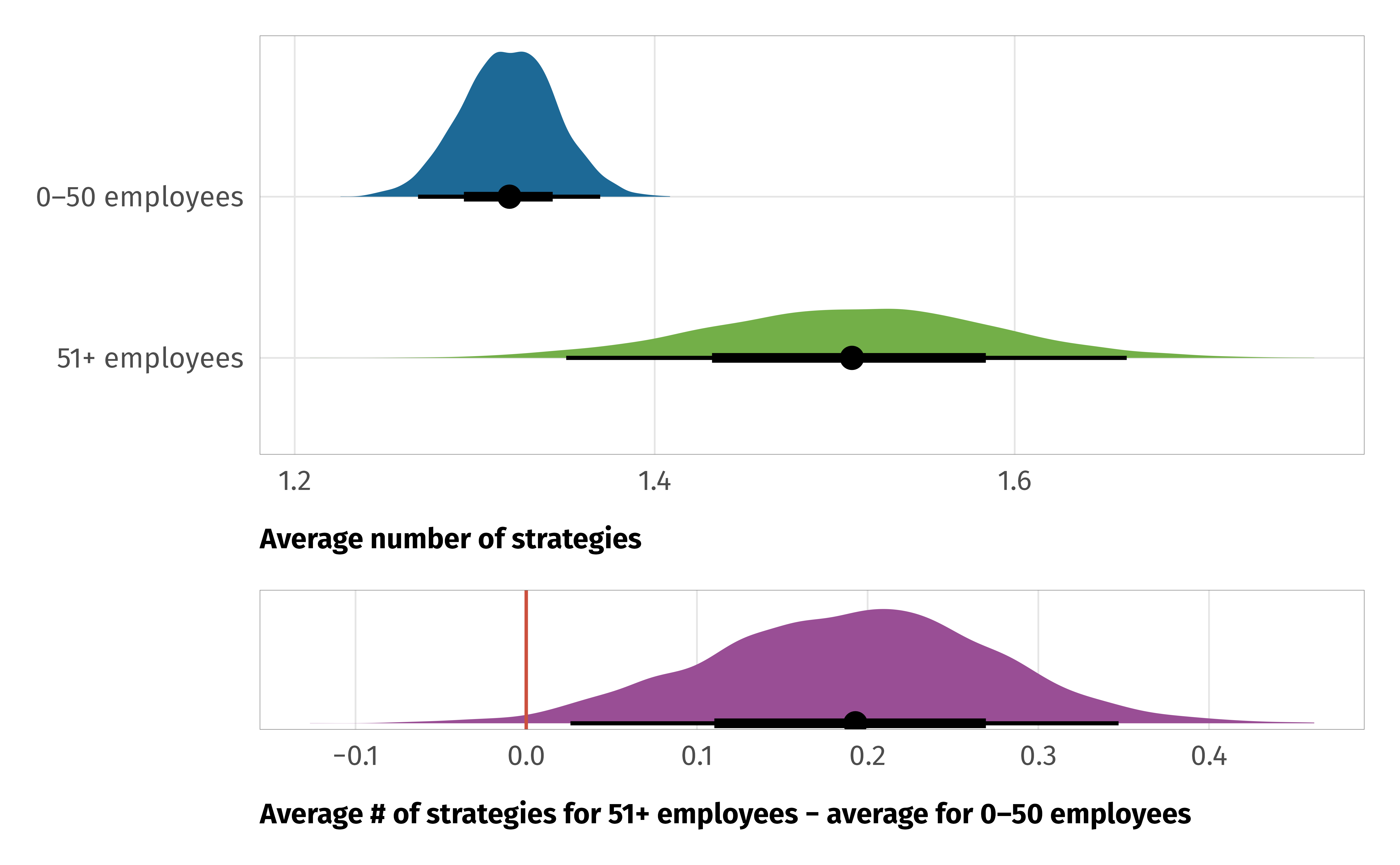
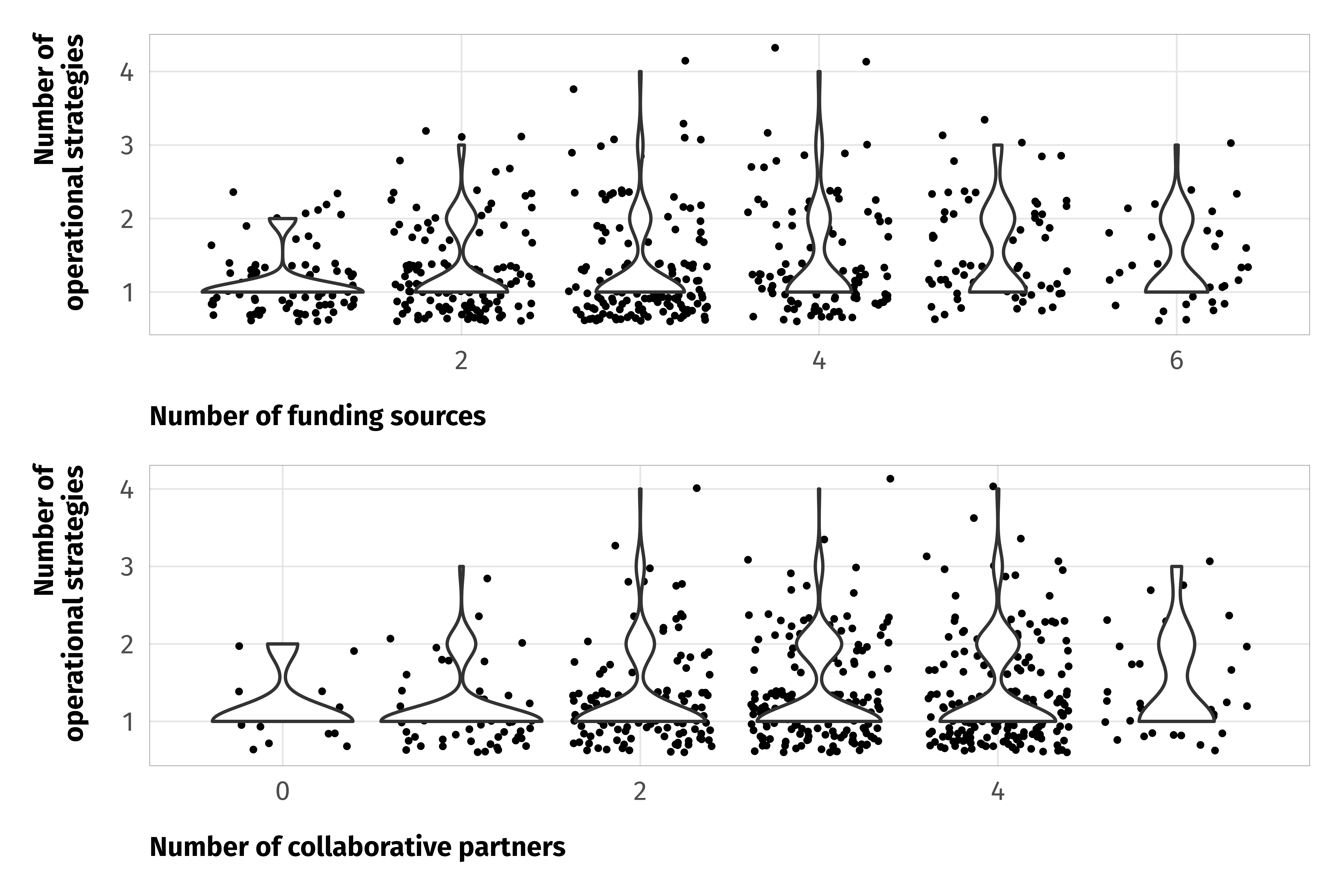
--- title: "INGOs and instrumental factors" format: html: code-fold: true --- ```{r setup, include=FALSE} :: opts_chunk$ set (fig.align = "center" , fig.retina = 3 ,fig.width = 6 , fig.height = (6 * 0.618 ),out.width = "80%" , collapse = TRUE ,dev = "ragg_png" )options (digits = 3 , width = 120 ,dplyr.summarise.inform = FALSE ,knitr.kable.NA = "" )``` ```{r load-libraries-data, warning=FALSE, message=FALSE} library (tidyverse)library (targets)library (scales)library (glue)library (gt)library (patchwork)library (tidybayes)library (here)tar_config_set (store = here ('_targets' ),script = here ('_targets.R' ))tar_load (c (survey_orgs, survey_countries, survey_all))tar_load (c (models_strategies_size))# Plotting functions invisible (list2env (tar_read (graphic_functions), .GlobalEnv))invisible (list2env (tar_read (table_functions), .GlobalEnv))set_annotation_fonts ()``` # Staffing ```{r tab-volunteers} <- survey_orgs %>% select (employees = Q3.4. num, volunteers = Q3.5. num) %>% filter (employees < 10000 , volunteers < 10000 ) %>% mutate (no_emps = employees == 0 ,no_vols = volunteers == 0 )%>% count (no_vols) %>% mutate (prop = n / sum (n)) %>% gt () %>% cols_label (no_vols = "No volunteers" ,n = "N" ,prop = "Proportion" %>% cols_align (align = "left" , columns = no_vols) %>% fmt_percent (columns = prop, decimals = 1 ) %>% opts_theme ()``` ```{r tab-staff-volunteers} %>% group_by (no_emps, no_vols) %>% summarize (across (c (employees, volunteers), list (n = ~ n (), median = median, mean = mean))) %>% ungroup () %>% mutate (prop = employees_n / sum (employees_n))%>% pivot_longer (c (employees, volunteers)) %>% mutate (name = str_to_title (name)) %>% ggplot (aes (x = value, fill = name)) + geom_histogram (binwidth = 0.5 , color = "white" , linewidth = 0.25 ) + scale_x_continuous (trans = "log1p" , breaks = c (0 , 10 ^ (0 : 5 )), labels = label_comma ()) + scale_fill_manual (values = c (clrs$ Prism[3 ], clrs$ Prism[6 ]), name = NULL ) + labs (x = NULL , y = "Number of staff" ) + facet_wrap (vars (name), nrow = 2 ) + theme_ingo ()``` # Funding ```{r tab-funding} <- survey_orgs %>% filter (! is.na (small_org)) %>% select (clean.id, small_org, Q3.8. num, Q3.8 ) %>% filter (! is.na (Q3.8. num))%>% group_by (small_org) %>% summarize (across (Q3.8. num, list (mean = mean, median = median))) %>% gt () %>% cols_label (small_org = "Organization size" ,Q3.8.num_mean = "Sources (mean)" ,Q3.8.num_median = "Sources (median)" %>% cols_align (align = "left" , columns = small_org) %>% opts_theme ()``` ```{r calc-funding-org-size} <- df_funding %>% unnest (Q3.8 ) %>% filter (key != "None" ) %>% group_by (key, value, small_org) %>% summarise (num = n ()) %>% ungroup () %>% mutate (value = factor (value,levels = levels (survey_orgs$ Q3.8 _individual),ordered = TRUE )) %>% mutate (answer = fct_collapse (value,"A lot" = c ("A great deal" , "A lot" ),"Some" = c ("A moderate amount" , "A little" ),"None" = "None at all" %>% filter (key != "Other" ) %>% mutate (source = fct_collapse (key,"NGOs and foundations" = c ("Donations from other NGOs" , "Foundation donations" ),"Governments and IGOs" = c ("Grants from home country" , "Grants from host country" , "Grants from other governments" , "Grants from IGOs" )``` ```{r plot-funding-org-size, fig.width=7, fig.height=5} <- df_funding_unnested_org_size %>% group_by (answer, source, small_org) %>% summarise (num = sum (num)) %>% group_by (small_org, source) %>% mutate (total = sum (num)) %>% ungroup () %>% mutate (prop = num / total) %>% arrange (answer, desc (small_org), desc (prop)) %>% mutate (source = fct_inorder (source))<- df_funding_plot %>% group_by (source) %>% summarise (total = sum (num)) %>% ungroup () %>% arrange (total) %>% mutate (source = fct_inorder (source))<- ggplot (df_funding_totals, aes (x = total, y = source)) + geom_pointrange (aes (xmin = 0 , xmax = after_stat (x))) + scale_x_continuous (breaks = c (0 , 500 , 1000 ),labels = label_comma ()) + labs (x = "Times answer selected" , y = NULL ,title = "INGO funding sources" ) + theme_ingo () + theme (panel.grid.major.y = element_blank ())<- ggplot (df_funding_plot, aes (x = prop, y = fct_rev (answer),color = fct_rev (small_org))) + geom_pointrange (aes (xmin = 0 , xmax = after_stat (x)),position = position_dodge (width = 0.75 ), size = 0.5 ) + scale_color_manual (values = c (clrs$ Prism[2 ], clrs$ Prism[5 ]), name = NULL ,guide = guide_legend (reverse = TRUE )) + scale_x_continuous (labels = label_percent ()) + labs (x = "Proportion selected" , y = NULL , title = "How much funding INGO relies on" ) + facet_wrap (vars (source)) + theme_ingo () + theme (strip.text = element_text (size = rel (0.75 )),panel.grid.major.y = element_blank (),legend.position = c (1 , 0 ), legend.justification = c (1 , 0 ),legend.direction = "vertical" )/ plot_spacer () / p2) + plot_layout (heights = c (0.325 , 0.025 , 0.65 ))``` # Time in country ```{r plot-time-in-country, fig.width=6, fig.height=3} <- survey_all %>% filter (! is.na (Q4.2 ), Q4.2 != "Don't know" ) %>% group_by (Q4.2 , target.regime.type) %>% summarise (num = n ()) %>% ungroup () %>% mutate (Q4.2 = factor (Q4.2 , levels = rev (levels (Q4.2 )), ordered = TRUE ))ggplot (df_time_country, aes (x = num, y = Q4.2 , color = target.regime.type)) + geom_pointrange (aes (xmin = 0 , xmax = after_stat (x)), position = position_dodge (width = 0.5 ), size = 0.5 ) + scale_x_continuous (sec.axis = sec_axis (~ . / sum (df_time_country$ num),labels = label_percent ())) + scale_color_manual (values = c (clrs$ Prism[4 ], clrs$ Prism[6 ]), name = NULL ,guide = guide_legend (reverse = TRUE )) + labs (x = "Number of responses" , y = NULL ) + theme_ingo () + theme (panel.grid.major.y = element_blank ())``` # Collaboration ```{r tab-collaboration} <- survey_orgs %>% filter (! is.na (small_org)) %>% select (clean.id, small_org, Q3.6 _clean) %>% unnest (Q3.6 _clean) %>% group_by (Q3.6 _clean) %>% summarise (num = n ()) %>% arrange (desc (num)) %>% gt () %>% cols_label (Q3.6_clean = "Partner" ,num = "N" %>% opts_theme ()``` ```{r plot-collaboration-size, fig.width=6, fig.height=3.5} <- df_collaboration_raw %>% filter (! (Q3.6 _clean %in% c ("Other" , "Individuals" , "Don't know" , "We do not collaborate with other organizations or institutions" ))) %>% mutate (Q3.6_clean = fct_collapse (Q3.6 _clean,"NGOs" = c ("Other nongovernmental organizations (NGOs)" ,"Academic organizations" ,"Faith-based organizations" ),"Corporations" = c ("Corporations or businesses" , "Media" ),"IGOs" = "International organizations (IGOs)" %>% group_by (small_org, Q3.6 _clean) %>% summarise (num = n ()) %>% group_by (small_org) %>% mutate (total = sum (num)) %>% ungroup () %>% mutate (prop = num / total) %>% arrange (small_org, prop) %>% mutate (Q3.6_clean = fct_inorder (Q3.6 _clean))ggplot (df_collaboration_plot, aes (x = prop, y = Q3.6 _clean, color = fct_rev (small_org))) + geom_pointrange (aes (xmin = 0 , xmax = after_stat (x)), position = position_dodge (width = 0.5 ), size = 0.5 ) + labs (x = "Proportion selected" , y = NULL ) + scale_color_manual (values = c (clrs$ Prism[2 ], clrs$ Prism[5 ]), name = NULL ,guide = guide_legend (reverse = TRUE )) + scale_x_continuous (labels = label_percent ()) + theme_ingo () + theme (panel.grid.major.y = element_blank ())``` # Flexibility and practical strategies ## Size and number of changes ```{r plot-strategies-size} <- models_strategies_size$ draws %>% ggplot (aes (x = .epred, y = fct_rev (small_org), fill = small_org)) + stat_halfeye () + scale_fill_manual (values = c (clrs$ Prism[2 ], clrs$ Prism[5 ]),guide = "none" ) + labs (x = "Average number of strategies" , y = NULL ) + theme_ingo ()<- models_strategies_size$ diffs %>% ggplot (aes (x = .epred)) + stat_halfeye (fill = clrs$ Prism[11 ]) + geom_vline (xintercept = 0 , linewidth = 0.5 , color = clrs$ Prism[8 ]) + scale_x_continuous (labels = label_number (style_negative = "minus" )) + labs (x = "Average # of strategies for 51+ employees − average for 0–50 employees" ,y = NULL ) + theme_ingo () + theme (axis.text.y = element_blank (),panel.grid.major.y = element_blank ())/ p2) + plot_layout (heights = c (0.75 , 0.25 ))<- survey_all %>% mutate (num_strategies = Q4.3 _value %>% map_int (length)) %>% filter (! is.na (Q4.3 _value), ! is.na (small_org))``` ```{r tab-strategies-size} $ draws %>% median_qi (.epred) %>% mutate (small_org = as.character (small_org),type = "Group medians" ) %>% rename (y = .epred, ymin = .lower, ymax = .upper) %>% bind_rows (models_strategies_size$ diffs_summary) %>% mutate (across (c (y, ymin, ymax, p_greater_0), list (nice = ~ label_number (accuracy = 0.01 )(.)))) %>% mutate (nice_value = glue ("{y_nice}<br>({ymin_nice}–{ymax_nice})" )) %>% mutate (small_org = str_replace (small_org, " - " , " − " )) %>% select (type, small_org, nice_value, p_greater_0_nice) %>% group_by (type) %>% gt () %>% cols_label (small_org = "" ,nice_value = "Posterior median" ,p_greater_0_nice = "p > 0" %>% fmt_markdown (nice_value) %>% sub_missing (p_greater_0_nice) %>% tab_footnote (footnote = "95% credible intervals shown in parentheses" ) %>% opts_theme ()``` ## Collaborations, funding sources, and number of strategies ```{r plot-strategies-funding-collaboration, fig.width=6, fig.height=4} <- survey_all %>% mutate (num_strategies = Q4.3 _value %>% map_int (length)) %>% filter (! is.na (Q4.3 _value), Q3.8. num < 7 ) %>% select (num_strategies, Q3.8. num)<- ggplot (df_strategies_funding, aes (x = Q3.8. num, y = num_strategies, group = Q3.8. num)) + geom_point (position = position_jitter (seed = 1234 ), size = 0.5 ) + geom_violin () + labs (x = "Number of funding sources" , y = "Number of \n operational strategies" ) + theme_ingo ()<- survey_all %>% mutate (num_strategies = Q4.3 _value %>% map_int (length),num_collaborations = Q3.6 _num) %>% filter (! is.na (Q4.3 _value), ! is.na (Q3.6 _num)) %>% select (num_strategies, num_collaborations)<- ggplot (df_strategies_collaboration, aes (x = num_collaborations, y = num_strategies, group = num_collaborations)) + geom_point (position = position_jitter (seed = 1234 ), size = 0.5 ) + geom_violin () + labs (x = "Number of collaborative partners" , y = "Number of \n operational strategies" ) + theme_ingo ()/ p2```