Models
Suparna Chaudhry and Andrew Heiss
2018-10-29
knitr::opts_chunk$set(cache = FALSE, fig.retina = 2,
tidy.opts = list(width.cutoff = 120), # For code
options(width = 120)) # For output
library(tidyverse)
library(stringr)
library(forcats)
library(stargazer)
library(huxtable)
library(lme4)
library(modelr)
library(broom)
library(broom.mixed)
library(scales)
library(formula.tools)
library(here)
source(here("lib", "graphics.R"))
source(here("lib", "pandoc.R"))
source(here("lib", "bayes.R"))
source(here("lib", "robustness_models_definitions.R"))
source(here("lib", "h1_model_definitions.R"))
source(here("lib", "h2_model_definitions.R"))
source(here("lib", "h3_model_definitions.R"))
my.seed <- 1234
set.seed(my.seed)df.country.aid <- readRDS(here("Data", "data_clean",
"df_country_aid_no_imputation.rds"))
df.country.aid.impute <- readRDS(here("Data", "data_clean",
"df_country_aid_imputation.rds"))
df.country.aid.impute.m10 <- readRDS(here("Data", "data_clean",
"df_country_aid_imputation_m10.rds"))
dcjw.questions.clean <- read_csv(here("Data", "data_manual", "dcjw_questions.csv"))
dcjw.responses.clean <- read_csv(here("Data", "data_manual", "dcjw_responses.csv"))
# Load clean coefficient names and append "within" and "between" to them,
# resulting in a giant table of possible coefficient names
coef.names <- read_csv(here("Data", "data_manual", "coef_names.csv"))
coef.names.within <- coef.names %>%
mutate(term = paste0(term, "_within"),
term_plot = paste0(term_clean, "\n(within)"),
term_plot_short = term_clean,
term_clean = paste0(term_clean, "~within~"))
coef.names.between <- coef.names %>%
mutate(term = paste0(term, "_between"),
term_plot = paste0(term_clean, "\n(between)"),
term_plot_short = paste0(term_clean, ""),
term_clean = paste0(term_clean, "~between~"))
coef.names.all <- bind_rows(coef.names, coef.names.within, coef.names.between) %>%
mutate_at(vars(term_plot, term_plot_short),
funs(ifelse(is.na(.), term_clean, .))) %>%
mutate(term_plot_short = recode(term_plot_short,
`Civil society reg. env. (CSRE)` = "CSRE"))
# Load clean model names
model.names <- read_csv(here("Data", "data_manual", "model_names.csv"))
# Combine original data and imputed data so calculations can happen at the same time
df.country.aid.both <- bind_rows(df.country.aid, df.country.aid.impute)
# Combine m=10 imputed data too since we use it in some robustness checks.
# Imputations 6-10 are later removed
df.country.aid.all <- bind_rows(df.country.aid, df.country.aid.impute.m10)
# All the missing values have been taken care of, but final years for leaded
# variables *are* still missing (i.e. there's no aid data for 2014, so
# total.oda_log_next_year will be NA in 2013). For this fancy random effects
# regression to work, the demeaned variables have to be based on the means of
# all rows included in the regression, so they can't include rows that are
# dropped because of missingness. This means we have to make separate demeaned
# datasets for *_after_2 and *_after_5, but ¯\_(ツ)_/¯
df.country.aid.demean.next_year.all <- df.country.aid.all %>%
filter(!is.na(total.oda_log_next_year)) %>%
group_by(m, cowcode) %>%
mutate_at(vars(barriers.total, advocacy, entry, funding,
polity, gdp.capita_log, gdp.capita, trade.pct.gdp, corruption, csre,
total.oda_log),
funs(between = mean(., na.rm = TRUE), # meaned
within = . - mean(., na.rm = TRUE))) %>% # demeaned
ungroup()
df.country.aid.us.demean.next_year.all <- df.country.aid.all %>%
filter(!is.na(prop.ngo.dom_logit_next_year)) %>%
filter(year > 1999) %>%
group_by(m, cowcode) %>%
mutate_at(vars(barriers.total, advocacy, entry, funding,
polity, gdp.capita_log, gdp.capita, trade.pct.gdp, corruption, csre,
total.oda_log),
funs(between = mean(., na.rm = TRUE), # meaned
within = . - mean(., na.rm = TRUE))) %>% # demeaned
ungroup()
# Divide demeaned data into separate data frames: original, imputed (m=5), and imputed (m=10)
df.country.aid.demean.next_year.both <-
filter(df.country.aid.demean.next_year.all, !(m %in% paste0("imp", 6:10)))
df.country.aid.demean.next_year <-
filter(df.country.aid.demean.next_year.all, m == "original")
df.country.aid.us.demean.next_year.both <-
filter(df.country.aid.us.demean.next_year.all, !(m %in% paste0("imp", 6:10)))
df.country.aid.us.demean.next_year <-
filter(df.country.aid.us.demean.next_year.all, m == "original")
df.country.aid.demean.next_year.impute <-
filter(df.country.aid.demean.next_year.all,
m != "original", !(m %in% paste0("imp", 6:10)))
df.country.aid.demean.next_year.impute.m10 <-
filter(df.country.aid.demean.next_year.all, m != "original")
# Demean data with total.oda_log leaded by 2 years and 5 years
# After 2 years
df.country.aid.demean.after_2.both <- df.country.aid.both %>%
filter(!is.na(total.oda_log_after_2)) %>%
group_by(m, cowcode) %>%
mutate_at(vars(barriers.total, advocacy, entry, funding,
polity, gdp.capita_log, gdp.capita, trade.pct.gdp, corruption, csre,
total.oda_log),
funs(between = mean(., na.rm = TRUE), # meaned
within = . - mean(., na.rm = TRUE))) %>% # demeaned
ungroup()
df.country.aid.demean.after_2 <-
filter(df.country.aid.demean.after_2.both, m == "original")
df.country.aid.demean.after_2.impute <-
filter(df.country.aid.demean.after_2.both, m != "original")
# After 5 years
df.country.aid.demean.after_5.both <- df.country.aid.both %>%
filter(!is.na(total.oda_log_after_5)) %>%
group_by(m, cowcode) %>%
mutate_at(vars(barriers.total, advocacy, entry, funding,
polity, gdp.capita_log, gdp.capita, trade.pct.gdp, corruption, csre,
total.oda_log),
funs(between = mean(., na.rm = TRUE), # meaned
within = . - mean(., na.rm = TRUE))) %>% # demeaned
ungroup()
df.country.aid.demean.after_5 <-
filter(df.country.aid.demean.after_5.both, m == "original")
df.country.aid.demean.after_5.impute <-
filter(df.country.aid.demean.after_5.both, m != "original")# Print correct huxtable table depending on the type of output.
#
# Technically this isn't completely necessary, since huxtable can output a
# markdown table, which is ostensibly universal for all output types. However,
# markdown tables are inherently limited in how fancy they can be (e.g. they
# don't support column spans), so I instead let the regression table use
# huxtable's fancy formatting for html and PDF and markdown everywhere else.
if (isTRUE(getOption('knitr.in.progress'))) {
file_format <- rmarkdown::all_output_formats(knitr::current_input())
} else {
file_format <- ""
}
print_hux <- function(x) {
if ("html_document" %in% file_format) {
print_html(x)
} else if ("pdf_document" %in% file_format) {
print_latex(x)
} else if ("word_document" %in% file_format) {
print_md(x)
} else {
print(x)
}
}stars <- function(p) {
out <- symnum(p, cutpoints = c(0, 0.01, 0.05, 0.1, 1),
symbols = c("***", "**", "*", ""))
as.character(out)
}
fixed.digits <- function(x, digits = 2) {
formatC(x, digits = digits, format = "f")
}
# Use 2 significant digits only on the decimal part of the number, ignoring the
# integer part. See my question here: http://stackoverflow.com/q/43050903/120898
# fixed.digits <- function(x, digits = 2) {
# as.character(floor(x) + signif(x %% 1, digits))
# }
# Inverse logit, with the ability to account for adjustments
# via http://stackoverflow.com/a/23845527/120898
inv.logit <- function(f, a) {
a <- (1 - 2 * a)
(a * (1 + exp(f)) + (exp(f) - 1)) / (2 * a * (1 + exp(f)))
}
# Take apart the pieces of a random effects formula and rebuild it
build.formula <- function(DV, IVs) {
terms.all <- attr(terms(IVs), "term.labels")
terms.fixed <- terms.all[!stringr::str_detect(terms.all, "\\|")]
terms.rand <- sapply(findbars(formula(IVs)),function(x) paste0("(", deparse(x), ")"))
reformulate(c(terms.fixed, terms.rand), response = DV)
}
get.rhs <- function(x) rhs.vars(x) %>% str_replace_all("1 \\| ", "")
get.lhs <- function(x) lhs.vars(x)
is_scaled <- function(x) "scaled:scale" %in% names(attributes(x))
get_scale <- function(x) attr(x, "scaled:scale")
# Meld a bunch of imputed models
meld.imputed.models <- function(model.data, exponentiate = FALSE) {
models.df <- model.data$glance[[1]]$df.residual
models.tidy <- model.data %>%
select(tidy) %>%
unnest(.id = "imputation")
just.estimates <- models.tidy %>%
filter(group == "fixed") %>%
select(imputation, term, estimate) %>%
spread(term, estimate) %>%
select(-imputation)
just.ses <- models.tidy %>%
filter(group == "fixed") %>%
select(imputation, term, std.error) %>%
spread(term, std.error) %>%
select(-imputation)
# If no imputed data was passed in, use the actual estimates and SEs
if (nrow(just.estimates) > 1) {
melded <- Amelia::mi.meld(just.estimates, just.ses)
} else {
melded <- list(q.mi = just.estimates, se.mi = just.ses)
}
melded.tidy <- as.data.frame(cbind(t(melded$q.mi),
t(melded$se.mi))) %>%
magrittr::set_colnames(c("estimate", "std.error")) %>%
mutate(term = rownames(.)) %>%
select(term, everything()) %>%
mutate(statistic = estimate / std.error,
conf.low = estimate + std.error * qt(0.025, models.df),
conf.high = estimate + std.error * qt(0.975, models.df),
p.value = 2 * pt(abs(statistic), models.df, lower.tail = FALSE),
stars = stars(p.value))
if (exponentiate) {
# Convert SEs to odds ratios. This isn't entirely 100% accurate, since the
# melded coefficient variances (i.e. diag(vcov(.))) are just averaged, not
# melded with Amelia's fancy mi.meld(), but ¯\_(ツ)_/¯
#
# https://www.andrewheiss.com/blog/2016/04/25/convert-logistic-regression-standard-errors-to-odds-ratios-with-r/
fixed.coefs.var <- model.data %>%
mutate(var.diag = model %>% map(~ diag(vcov(.)))) %>%
select(var.diag, model) %>% unnest(var.diag)
just.var <- models.tidy %>%
filter(group == "fixed") %>%
select(imputation, term) %>%
bind_cols(fixed.coefs.var) %>%
group_by(term) %>%
summarise(var.diag = mean(var.diag))
melded.tidy <- melded.tidy %>%
left_join(just.var, by = "term") %>%
mutate(or = exp(estimate),
or.se = sqrt(or^2 * var.diag),
or.upper = or + (qnorm(0.975) * or.se),
or.lower = or + (qnorm(0.025) * or.se))
}
melded.tidy
}
# Expects a data frame with a column named tidy.melded and a row for model
# names. Term names are based on the first model in the data column for each
# row, and are filtered through stargazer to get the correct row order.
stargazer.fake <- function(df, caption = NULL, note = NULL, exponentiate = FALSE) {
# Create a blank row with a bolded row name
header.row <- function(header) {
data_frame(term = paste0("**", header, "**"),
models = df$model.name, value = "") %>%
spread(models, value)
}
note.row <- function(note) {
crossing(term = note,
models = df$model.name, value = "") %>%
spread(models, value) %>%
# Sort based on original note order
slice(match(note, term))
}
coef.order.models <- df %>%
# Select just the first row of each model
unnest(data) %>%
# Sometimes there are duplicate column names
# magrittr::set_colnames(make.unique(colnames(.))) %>%
# Keep order of model.name
mutate(model.name = ordered(fct_inorder(model.name))) %>%
group_by(model.name) %>%
slice(1) %>% ungroup() %>%
select(model) %>% as.list()
# Use stargazer to get the coefficient order. I tried recreating stargazer's
# coefficient ordering algorithm but it's way too complicated. So instead, we
# cheat and let stargazer do the heavy lifting, save the output to a string,
# and then extract the coefficient names with str_extract. Super super hacky,
# but it works.
#
# See http://stackoverflow.com/a/41801861/120898
capture.output({
stargazer.coefs <- stargazer::stargazer(coef.order.models,
type = "text", table.layout = "t")
}, file = "/dev/null")
coef.order <- setdiff(stringr::str_extract(stargazer.coefs, "^[\\w\\.]*"), c(""))
# Fixed parts
fixed.tidy <- df %>%
unnest(tidy.melded)
if (exponentiate) {
fixed.coefs <- fixed.tidy %>%
mutate(fancy = paste0(fixed.digits(or, 3),
stars, "\\ \n(",
fixed.digits(or.se, 3),
")"))
} else {
fixed.coefs <- fixed.tidy %>%
mutate(fancy = paste0(fixed.digits(estimate, 3),
stars, "\\ \n(",
fixed.digits(std.error, 3),
")"))
}
fixed.coefs <- fixed.coefs %>%
select(model.name, term, fancy) %>%
spread(model.name, fancy, fill = "") %>%
# Clean up term names
mutate(term = stringr::str_replace(term, "TRUE$|FALSE$", ""),
term = recode(term, `(Intercept)` = "Constant")) %>%
# Use stargazer's coefficient order
mutate(term = factor(term, levels = coef.order, ordered = TRUE)) %>%
arrange(term) %>%
mutate(term = as.character(term)) %>%
left_join(coef.names.all, by = "term") %>%
mutate(term_clean = ifelse(term == "Constant", "Constant", term_clean)) %>%
select(-term) %>% rename(term = term_clean) %>%
select_(.dots = c("term", df$model.name))
# Random parts
random.coef.order.raw <- df %>%
unnest(data) %>%
# unnest(data) %>% magrittr::set_colnames(make.unique(colnames(.))) %>%
select(model.name, model) %>%
mutate(ranef = model %>% map(~ as.data.frame(VarCorr(.)))) %>%
unnest(ranef)
random.coef.order <- c(setdiff(unique(random.coef.order.raw$grp), "Residual"), "Residual")
random.coefs <- df %>%
unnest(data) %>%
unnest(tidy) %>%
filter(group != "fixed") %>%
rename(term.raw = term, term = group) %>%
group_by(model.name, term) %>%
summarise(avg.random.sd = mean(estimate),
sd.random.sd = sd(estimate)) %>%
mutate(fancy = paste0(fixed.digits(avg.random.sd, 3),
"\\ \n(",
ifelse(is.na(sd.random.sd), "NA", fixed.digits(sd.random.sd, 3)),
")")) %>%
select(model.name, term, fancy) %>%
spread(model.name, fancy, fill = "") %>%
mutate(term = factor(term, levels = random.coef.order, ordered = TRUE)) %>%
arrange(term) %>% mutate(term = as.character(term)) %>%
left_join(coef.names.all, by = "term") %>%
mutate(term_clean = ifelse(term == "Residual",
"Residual random error ($\\sigma$)", term_clean)) %>%
select(-term) %>% select(term = term_clean, everything())
# Create the bottom half of the table
# Calculate the average log likelihood for all imputed models
avg.loglik <- df %>%
unnest(data) %>% unnest(glance) %>%
group_by(model.name) %>%
summarise(avg.loglik = as.character(round(mean(logLik), 2))) %>%
mutate(term = "Log likelihood (mean)") %>%
spread(model.name, avg.loglik)
# Imputation frames
n.obs <- df %>%
unnest(data) %>%
mutate(n = model %>% map_int(~ nrow(.@frame))) %>%
select(model.name, n) %>%
group_by(model.name) %>% slice(1) %>% ungroup() %>%
mutate(term = "Observations",
n = scales::comma(n)) %>%
spread(model.name, n)
n.m <- df %>%
mutate(m.new = data %>% map_int(~ nrow(.))) %>%
select(model.name, m.new) %>%
mutate(m.new = ifelse(m.new == 1, 0, m.new),
m.new = as.character(m.new)) %>%
mutate(term = "Imputed datasets (*m*)") %>%
spread(model.name, m.new)
bottom.details <- bind_rows(n.obs, avg.loglik, n.m)
if (exponentiate) {
fixed.title <- "Fixed part (odds ratios)"
random.title <- "Random part (original coefficients)"
} else {
fixed.title <- "Fixed part"
random.title <- "Random part"
}
if (!is.null(note)) {
notes <- bind_rows(header.row("Notes"), note.row(note))
} else {
notes <- NULL
}
nice.top.bottom <- bind_rows(header.row(fixed.title), fixed.coefs,
header.row(random.title), random.coefs,
header.row("Model details"), bottom.details,
notes) %>%
select_(.dots = c("term", df$model.name))
# Make column names (1), (2), etc.
# TODO: Allow for custom column names
colnames(nice.top.bottom) <- c(" ", paste0("(", 1:length(df$model.name), ")"))
# All columns are centered except the first
# TODO: MAYBE: Let this be user configurable
table.align <- paste0(c("l", rep("c", length(df$model.name))), collapse = "")
pandoc.table.return(nice.top.bottom, keep.line.breaks = TRUE,
justify = table.align, caption = caption)
}Dependent variables
As explained in each section below, we have to transform and operationalize the dependent variable (foreign aid) in different ways for each hypothesis. The table belows summarizes each simplified model specification.
\[ \begin{aligned} \boldsymbol{H_1}&: ln( \text{ODA}_{\text{OECD}} )_{i, t+1} &= \text{NGO legislation}_{it} + \text{controls}_{it} \\ \boldsymbol{H_2}&: ln( \frac{\text{contentious ODA}_{\text{OECD}}}{\text{noncontentious ODA}_{\text{OECD}}} )_{i, t+1} &= \text{NGO legislation}_{it} + \text{controls}_{it} \\ \boldsymbol{H_3}&: ln( \frac{\text{Aid to (domestic or foreign) NGOs}_{\text{USAID}}}{\text{Aid to other channels}_{\text{USAID}}} )_{i, t+1} &= \text{NGO legislation}_{it} + \text{controls}_{it} \end{aligned} \] {#eq:all-models-dvs}
General model specifications and controls
We use a standard set of controls in each model (explained in more detail here):
- Democracy:
polity - Wealth:
gdp.capita_log(logged so it’s on the same scale as the other variables) - Government capacity:
corruption - Bad stuff:
internal.conflict.past.5andnatural_disaster.occurrence
Following Bell and Jones (2015), we use crossed random effects for country and year and use a combination of meaned and demeaned versions of each continuous variable to estimate both the within and between effects of each variable.
\[ y_{i, t + 1} = \beta_0 + \beta_1 (x_{it} - \bar{x}_i) + \beta_2 \bar{x}_i + \ldots \]
This approach has multiple benefits. The coefficients for the demeaned variables are roughly equivalent to their corresponding coefficients in a fixed effects model, but a fixed effects model assumes that the between effect (captured by the mean variables) is 0, which is not the case. A random effects model specified in this manner is more interpretable, as it clearly separates the within and between effects (again, within = demeaned, between = mean).
Here’s proof of how it works in some simple models. Model 1 is a basic OLS with country fixed effects. Model 2 is a basic OLS with country random effects, but potentially misspecified, since the between and within effects are conflated. Model 3 is a basic OLS with country random effects specified with between (mean; \(\bar{x}_i\)) and within (demeaned; \(x_{it} - \bar{x}_i\)) coefficients. The demeaned/within coefficients in Model 3 are identical to the fixed effects coefficients in Model 1. If rows had been dropped because of listwise deletion (like, if there were missing values in one of independent variables), the coefficients would be slightly off, since the demeaned values would have been based on group means that included the values that were dropped (e.g. all 2013 rows are dropped because of lags, but the group means included 2013). This isn’t a problem in these reduced models, but that’s one reason we impute all the data—we need the data to be as complete as possible to get the most accurate random effects.
mod.test.fe <- lm(total.oda_log_next_year ~ barriers.total + polity +
as.factor(cowcode),
data = df.country.aid.demean.next_year)
mod.test.re <- lmer(total.oda_log_next_year ~ barriers.total + polity +
(1 | cowcode),
data = df.country.aid.demean.next_year)
mod.test.re.fancy <- lmer(total.oda_log_next_year ~
barriers.total_between + barriers.total_within +
polity_between + polity_within +
(1 | cowcode),
data = df.country.aid.demean.next_year)
# Make named list of coefficients to include in the table
all_coefs <- data_frame(model = list(mod.test.fe, mod.test.re, mod.test.re.fancy)) %>%
mutate(tidy = model %>% map(tidy)) %>%
unnest(tidy) %>%
filter(!str_detect(term, "cowcode"), (effect != "ran_pars" | is.na(effect))) %>%
filter(!duplicated(term, fromLast = TRUE)) %>%
filter(term != "(Intercept)") %>%
left_join(coef.names.all, by = "term")
coefs_named <- all_coefs %>% pull(term) %>%
set_names(all_coefs$term_clean)
tbl_example <- huxreg(mod.test.fe, mod.test.re, mod.test.re.fancy,
coefs = c(coefs_named, Constant = "(Intercept)"),
stars = NULL, statistics = c(N = "nobs"), note = "") %>%
insert_row(c("Country effects", "Fixed", "Random", "Random"),
after = nrow(.) - 2, copy_cell_props = FALSE) %>%
# Highlight identical cells
set_bold(2:5, 2, TRUE) %>%
set_bold(c(8, 9, 12, 13), 4, TRUE)
tbl_example %>% print_hux()| (1) | (2) | (3) | |
| Total legal barriers | -0.091 | -0.056 | |
| (0.089) | (0.085) | ||
| Polity IV (0–10) | 0.267 | 0.226 | |
| (0.045) | (0.043) | ||
| Total legal barriersbetween | -0.132 | ||
| (0.323) | |||
| Total legal barrierswithin | -0.091 | ||
| (0.089) | |||
| Polity IV (0–10)between | -0.165 | ||
| (0.155) | |||
| Polity IV (0–10)within | 0.267 | ||
| (0.045) | |||
| Constant | 17.911 | 16.739 | 18.826 |
| (1.147) | (0.446) | (1.213) | |
| Country effects | Fixed | Random | Random |
| N | 4416 | 4416 | 4416 |
tbl_example %>%
to_md(max_width = 100) %>%
cat(file = here("Output", "tbl-within-between-example.md"))
All of the models we run use imputed data (\(m = 5\)) with crossed year and country random effects. Most explanatory and control variables are included in their meaned and demeaned forms, except for any indicator variables (since you can’t really average binary data). Additionally, we include the regular form of the current year’s ODA to account for temporal autocorrelation in aid. We do not split current ODA into within and between versions so that mathematically it can be subtracted out of the next year’s ODA in the dependent variable. Other mixed models functions like nlme::lme() allow you to define autoregressive correlation structures, but lme4::lmer() doesn’t, so we account for time with this differenced approach instead. It’s not perfect, but it works:
mod.test.no.oda <- lmer(total.oda_log_next_year ~
barriers.total_between + barriers.total_within +
polity_between + polity_within +
gdp.capita_log_between + gdp.capita_log_within +
(1 | cowcode) + (1 | year),
data = filter(df.country.aid.demean.next_year.impute,
m == "imp1"))
mod.test.oda.split <- lmer(total.oda_log_next_year ~
barriers.total_between + barriers.total_within +
polity_between + polity_within +
total.oda_log_between + total.oda_log_within +
gdp.capita_log_between + gdp.capita_log_within +
(1 | cowcode) + (1 | year),
data = filter(df.country.aid.demean.next_year.impute,
m == "imp1"))
mod.test.oda.nosplit <- lmer(total.oda_log_next_year ~
barriers.total_between + barriers.total_within +
polity_between + polity_within +
total.oda_log +
gdp.capita_log_between + gdp.capita_log_within +
(1 | cowcode) + (1 | year),
data = filter(df.country.aid.demean.next_year.impute,
m == "imp1"))
resid.no.oda <- acf(residuals(mod.test.no.oda), plot = FALSE)
resid.oda <- acf(residuals(mod.test.oda.nosplit), plot = FALSE)
ci.line <- qnorm((1 + 0.95) / 2) / sqrt(resid.no.oda$n.used)
acf.plot.data <- bind_rows(
data_frame(Lag = resid.no.oda$lag[,,1], ACF = resid.no.oda$acf[,,1],
model = "No ODA"),
data_frame(Lag = resid.oda$lag[,,1], ACF = resid.oda$acf[,,1],
model = "Current year’s ODA")
)
ggplot(acf.plot.data, aes(x = Lag, y = ACF, fill = model)) +
geom_bar(stat = "identity", position = position_dodge(width = 1), width = 0.5) +
geom_hline(yintercept = 0, size = 1) +
geom_hline(yintercept = c(ci.line, -ci.line), size = 0.5, linetype = "dashed") +
guides(fill = guide_legend(title = NULL)) +
theme_donors()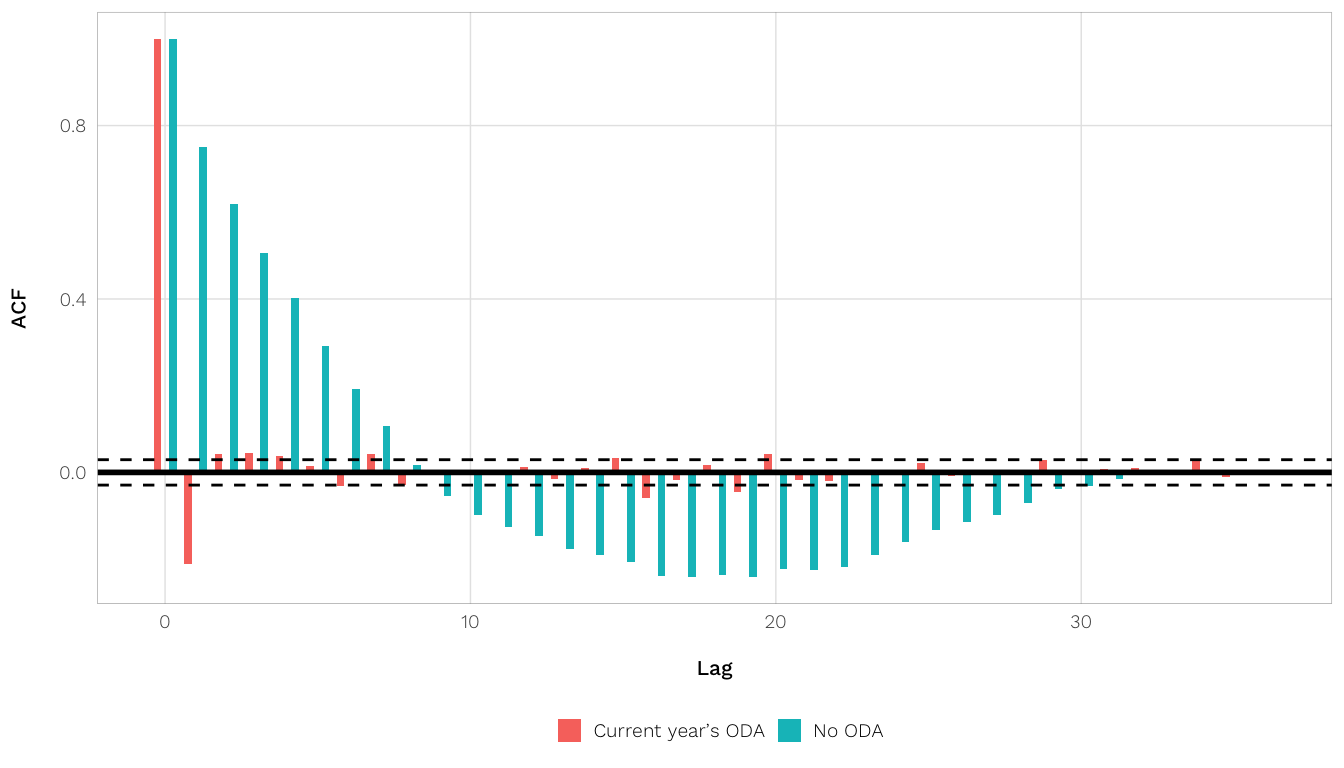
Not splitting current ODA into within and between also fixes another sticky mathematical issue. When the models are run with within and current ODA, the \(\sigma\) value for within-country variability becomes 0 for whatever reason (maybe it swallows up too much country level variability?). When \(\sigma = 0\), the between-group variability is too small to fully account for between effects, resulting in a “degenerate model” (see pages 10–11 here) and influencing the coefficients in weird ways. See below, where Model 1 uses the split current ODA and Model 2 doesn’t: \(\sigma\) in Model 2 exists and the coefficients are better estimated.
huxreg(mod.test.oda.split, mod.test.oda.nosplit,
tidy_args = list(effects = "fixed"),
statistics = c(N = "nobs"))## Warning in FUN(X[[i]], ...): tidy() does not return p values for models of class data.frame; significance stars not
## printed.
## Warning in FUN(X[[i]], ...): tidy() does not return p values for models of class data.frame; significance stars not
## printed.| (1) | (2) | |
| (Intercept) | 1.573 | 4.000 |
| (0.396) | (0.331) | |
| barriers.total_between | -0.053 | -0.044 |
| (0.037) | (0.037) | |
| barriers.total_within | -0.032 | -0.009 |
| (0.053) | (0.054) | |
| polity_between | -0.008 | 0.003 |
| (0.019) | (0.019) | |
| polity_within | -0.038 | -0.036 |
| (0.027) | (0.027) | |
| total.oda_log_between | 0.972 | |
| (0.010) | ||
| total.oda_log_within | 0.823 | |
| (0.009) | ||
| gdp.capita_log_between | -0.113 | -0.236 |
| (0.036) | (0.035) | |
| gdp.capita_log_within | -0.315 | -0.203 |
| (0.147) | (0.148) | |
| total.oda_log | 0.885 | |
| (0.007) | ||
| N | 4480 | 4480 |
| *** p < 0.001; ** p < 0.01; * p < 0.05. | ||
bind_rows(
as.data.frame(VarCorr(mod.test.oda.split)) %>% mutate(model = "(1)"),
as.data.frame(VarCorr(mod.test.oda.nosplit)) %>% mutate(model = "(2)")
) %>%
mutate(grp = ordered(fct_inorder(grp))) %>%
select(`Random variable` = grp, sdcor, model) %>%
spread(model, sdcor) %>% pandoc.table()| Random variable | (1) | (2) |
|---|---|---|
| cowcode | 0 | 0 |
| year | 0.4206 | 0.3629 |
| Residual | 2.661 | 2.699 |
Results
The results of all models can be found in the “Bayesian models” notebook, since it takes so many hours to run them all.
Summary of hypotheses
findings.summary <- read_csv(here("Data", "data_manual", "findings_summary.csv"))
caption <- "Summary of findings {#tbl:findings-summary}"
findings.summary.table <- pandoc.table.return(findings.summary, justify = "lll",
keep.line.breaks = TRUE, style = "grid",
caption = caption)
cat(findings.summary.table)| Proposition | Finding | |
|---|---|---|
| If countries adopt restrictive NGO legislation… | ||
| H1 | …donors will reduce foreign aid |
|
| H2 | …donors will increase aid for tamer causes and reduce aid for politically sensitive causes |
|
| H3 | …donors will channel more aid through domestic NGOs and channel less aid through foreign NGOs |
|
Robustness checks
Imputation
As discussed over in the data cleaning file, we impute data for the few variables that are missing. To show what difference imputation makes, the table below shows three pairs of models from H1. The first two models are run on non-imputed data (so missing observations are deleted listwise), the second two models are run on 5 sets of imputed data, and the last two models are run on 10 sets of imputed data.
It’s clear that imputation makes a substantial difference—note the big differences between coefficients. However, the number of imputed datasets doesn’t seem to matter, since there are only trivial differences in coefficients when there are 5 and 10 datasets.
mods.robust.check.m.next_year.raw <- df.country.aid.demean.next_year.all %>%
nest(-m) %>%
mutate(mod.h1.barriers.total = data %>%
future_map(mod.h1.barriers.total,
"total.oda_log_next_year"),
mod.h1.type.total = data %>%
future_map(mod.h1.type.total,
"total.oda_log_next_year"))
# Get model details and parameters
mods.robust.check.m.next_year <- mods.robust.check.m.next_year.raw %>%
gather(model.name, model, -m, -data) %>%
mutate(glance = model %>% map(broom::glance),
tidy = model %>% map(broom::tidy, conf.int = TRUE))
# Meld the imputed models
mods.robust.check.m.next_year.melded.original <- mods.robust.check.m.next_year %>%
filter(m == "original") %>%
group_by(model.name) %>%
nest() %>%
mutate(tidy.melded = data %>% map(meld.imputed.models))
mods.robust.check.m.next_year.melded.m5 <- mods.robust.check.m.next_year %>%
filter(m %in% paste0("imp", 1:5)) %>%
group_by(model.name) %>%
nest() %>%
mutate(tidy.melded = data %>% map(meld.imputed.models))
mods.robust.check.m.next_year.melded.m10 <- mods.robust.check.m.next_year %>%
filter(m != "original") %>%
group_by(model.name) %>%
nest() %>%
mutate(tidy.melded = data %>% map(meld.imputed.models))
mods.robust.check.m.next_year.melded.all <- bind_rows(
mods.robust.check.m.next_year.melded.original,
mods.robust.check.m.next_year.melded.m5,
mods.robust.check.m.next_year.melded.m10
) %>%
mutate(imputations = data %>% map_dbl(~ nrow(.)),
model.name = paste(model.name, imputations, sep = "_"))| (1) | (2) | (3) | (4) | (5) | (6) | |
|---|---|---|---|---|---|---|
| Fixed part | ||||||
| Total legal barrierswithin | 0.009 (0.051) |
-0.054 (0.054) |
-0.055 (0.054) |
|||
| Total legal barriersbetween | -0.004 (0.049) |
-0.051 (0.038) |
-0.051 (0.038) |
|||
| Barriers to advocacywithin | -0.141 (0.233) |
-0.424* (0.242) |
-0.424* (0.242) |
|||
| Barriers to advocacybetween | -0.067 (0.204) |
-0.096 (0.157) |
-0.096 (0.157) |
|||
| Barriers to entrywithin | 0.224** (0.114) |
0.104 (0.122) |
0.103 (0.122) |
|||
| Barriers to entrybetween | 0.004 (0.091) |
0.116 (0.071) |
0.116 (0.071) |
|||
| Barriers to fundingwithin | -0.120 (0.131) |
-0.032 (0.140) |
-0.033 (0.139) |
|||
| Barriers to fundingbetween | 0.010 (0.101) |
-0.166** (0.070) |
-0.166** (0.070) |
|||
| Polity IV (0–10)within | 0.054** (0.027) |
0.050* (0.027) |
-0.057** (0.028) |
-0.061** (0.028) |
-0.060** (0.028) |
-0.064** (0.028) |
| Polity IV (0–10)between | 0.045* (0.026) |
0.045* (0.026) |
0.010 (0.020) |
0.006 (0.021) |
0.010 (0.020) |
0.005 (0.021) |
| GDP per capita (log)within | -0.288* (0.160) |
-0.277* (0.160) |
-0.397** (0.180) |
-0.405** (0.181) |
-0.402** (0.165) |
-0.407** (0.164) |
| GDP per capita (log)between | -0.275*** (0.050) |
-0.274*** (0.051) |
-0.177*** (0.040) |
-0.173*** (0.040) |
-0.177*** (0.040) |
-0.173*** (0.040) |
| Trade as % of GDPwithin | -0.004* (0.002) |
-0.003* (0.002) |
-0.004* (0.002) |
-0.004 (0.002) |
-0.004* (0.002) |
-0.004* (0.002) |
| Trade as % of GDPbetween | -0.002 (0.001) |
-0.002 (0.001) |
-0.002 (0.001) |
-0.002 (0.001) |
-0.002 (0.001) |
-0.002 (0.001) |
| Corruptionwithin | 0.139*** (0.044) |
0.142*** (0.044) |
0.052 (0.045) |
0.053 (0.045) |
0.051 (0.048) |
0.052 (0.048) |
| Corruptionbetween | 0.120*** (0.028) |
0.120*** (0.029) |
0.049** (0.023) |
0.047** (0.023) |
0.049** (0.023) |
0.047** (0.023) |
| Total aid in present year (log) | 0.750*** (0.010) |
0.750*** (0.010) |
0.872*** (0.007) |
0.868*** (0.007) |
0.872*** (0.007) |
0.868*** (0.007) |
| Internal conflict in last 5 years | -0.049 (0.104) |
-0.052 (0.105) |
0.074 (0.102) |
0.065 (0.103) |
0.073 (0.102) |
0.064 (0.102) |
| Natural disasters | 0.048*** (0.016) |
0.046*** (0.016) |
0.035** (0.014) |
0.034** (0.014) |
0.035** (0.014) |
0.034** (0.014) |
| After 1989 | -0.054 (0.177) |
-0.062 (0.176) |
0.557*** (0.151) |
0.583*** (0.150) |
0.565*** (0.151) |
0.591*** (0.150) |
| Constant | 6.092*** (0.576) |
6.105*** (0.585) |
3.104*** (0.450) |
2.999*** (0.452) |
3.104*** (0.451) |
2.999*** (0.452) |
| Random part | ||||||
| Within-country variability (\(\sigma\)) | 0.401 (NA) |
0.407 (NA) |
0.000 (0.000) |
0.000 (0.000) |
0.000 (0.000) |
0.000 (0.000) |
| Within-year variability (\(\sigma\)) | 0.346 (NA) |
0.342 (NA) |
0.260 (0.006) |
0.254 (0.006) |
0.258 (0.004) |
0.253 (0.004) |
| Residual random error (\(\sigma\)) | 2.422 (NA) |
2.422 (NA) |
2.693 (0.001) |
2.691 (0.001) |
2.693 (0.001) |
2.691 (0.001) |
| Model details | ||||||
| Observations | 4,067 | 4,067 | 4,480 | 4,480 | 4,480 | 4,480 |
| Log likelihood (mean) | -9462.17 | -9462.5 | -10843.41 | -10840.76 | -10842.91 | -10840.29 |
| Imputed datasets (m) | 0 | 0 | 5 | 5 | 10 | 10 |
Neutral regulations
mods.robust.neutral.regs.raw <- df.country.aid.demean.next_year.all %>%
nest(-m) %>%
mutate(mod.h1.neutral.reg = data %>%
future_map(mod.h1.neutral.reg,
"total.oda_log_next_year"),
mod.h1.neutral.fund = data %>%
future_map(mod.h1.neutral.fund,
"total.oda_log_next_year"),
mod.h2.neutral.reg = data %>%
future_map(mod.h2.neutral.reg,
"prop.contentious_logit_next_year"),
mod.h2.neutral.fund = data %>%
future_map(mod.h2.neutral.fund,
"prop.contentious_logit_next_year"))
mods.robust.neutral.regs.raw.h3 <- df.country.aid.us.demean.next_year.both %>%
nest(-m) %>%
mutate(mod.h3.dom.neutral.reg = data %>%
future_map(mod.h3.dom.neutral.reg,
"prop.ngo.dom_logit_next_year"),
mod.h3.dom.neutral.fund = data %>%
future_map(mod.h3.dom.neutral.fund,
"prop.ngo.dom_logit_next_year"),
mod.h3.for.neutral.reg = data %>%
future_map(mod.h3.for.neutral.reg,
"prop.ngo.foreign_logit_next_year"),
mod.h3.for.neutral.fund = data %>%
future_map(mod.h3.for.neutral.fund,
"prop.ngo.foreign_logit_next_year"))
# Get model details and parameters
mods.robust.neutral.regs <- mods.robust.neutral.regs.raw %>%
gather(model.name, model, -m, -data) %>%
mutate(glance = model %>% map(broom::glance),
tidy = model %>% map(broom::tidy, conf.int = TRUE))
mods.robust.neutral.regs.h3 <- mods.robust.neutral.regs.raw.h3 %>%
gather(model.name, model, -m, -data) %>%
mutate(glance = model %>% map(broom::glance),
tidy = model %>% map(broom::tidy, conf.int = TRUE))
# Meld the imputed models
mods.robust.neutral.regs.melded.h1 <- mods.robust.neutral.regs %>%
filter(m != "original", str_detect(model.name, "h1")) %>%
group_by(model.name) %>%
nest() %>%
mutate(tidy.melded = data %>% map(meld.imputed.models))
mods.robust.neutral.regs.melded.h2 <- mods.robust.neutral.regs %>%
filter(m != "original", str_detect(model.name, "h2")) %>%
group_by(model.name) %>%
nest() %>%
mutate(tidy.melded = data %>% map(~ meld.imputed.models(., exponentiate = TRUE)))
mods.robust.neutral.regs.melded.h3 <- mods.robust.neutral.regs.h3 %>%
filter(m != "original") %>%
group_by(model.name) %>%
nest() %>%
mutate(tidy.melded = data %>% map(~ meld.imputed.models(., exponentiate = TRUE)))Neutral regulations and overall aid (H1)
table.robust.neutral.regs.h1 <- mods.robust.neutral.regs.melded.h1 %>%
stargazer.fake(exponentiate = FALSE) %>%
cat()| (1) | (2) | |
|---|---|---|
| Fixed part | ||
| Registration requirement | -0.103 (0.091) |
|
| Funding disclosure requirement | -0.088 (0.092) |
|
| GDP per capita (log)within | -0.409** (0.164) |
-0.411** (0.164) |
| GDP per capita (log)between | -0.165*** (0.040) |
-0.169*** (0.039) |
| Trade as % of GDPwithin | -0.004* (0.002) |
-0.004* (0.002) |
| Trade as % of GDPbetween | -0.002 (0.001) |
-0.002* (0.001) |
| Corruptionwithin | 0.055 (0.049) |
0.054 (0.049) |
| Corruptionbetween | 0.041* (0.021) |
0.040* (0.021) |
| Total aid in present year (log) | 0.874*** (0.007) |
0.873*** (0.007) |
| Internal conflict in last 5 years | 0.090 (0.101) |
0.095 (0.101) |
| Natural disasters | 0.031** (0.014) |
0.032** (0.014) |
| After 1989 | 0.474*** (0.148) |
0.468*** (0.148) |
| Constant | 3.075*** (0.430) |
3.135*** (0.426) |
| Random part | ||
| Within-country variability (\(\sigma\)) | 0.000 (0.000) |
0.000 (0.000) |
| Within-year variability (\(\sigma\)) | 0.273 (0.005) |
0.274 (0.005) |
| Residual random error (\(\sigma\)) | 2.694 (0.001) |
2.694 (0.001) |
| Model details | ||
| Observations | 4,480 | 4,480 |
| Log likelihood (mean) | -10837.94 | -10838.11 |
| Imputed datasets (m) | 10 | 10 |
Neutral regulations and tamer causes (H2)
table.robust.neutral.regs.h2 <- mods.robust.neutral.regs.melded.h2 %>%
filter(str_detect(model.name, "h2")) %>%
stargazer.fake(exponentiate = TRUE) %>%
cat()| (1) | (2) | |
|---|---|---|
| Fixed part (odds ratios) | ||
| Registration requirement | 1.009 (0.072) |
|
| Funding disclosure requirement | 0.908 (0.066) |
|
| Polity IV (0–10)within | 1.029* (0.016) |
1.029* (0.016) |
| Polity IV (0–10)between | 1.092*** (0.023) |
1.091*** (0.022) |
| GDP per capita (log)within | 0.973 (0.089) |
0.976 (0.089) |
| GDP per capita (log)between | 0.699*** (0.032) |
0.701*** (0.032) |
| Trade as % of GDPwithin | 0.998* (0.001) |
0.998* (0.001) |
| Trade as % of GDPbetween | 1.002* (0.001) |
1.002* (0.001) |
| Corruptionwithin | 1.054** (0.027) |
1.057** (0.027) |
| Corruptionbetween | 1.067** (0.028) |
1.066** (0.027) |
| Proportion of contentious aid in present year (logit) | 1.280*** (0.019) |
1.281*** (0.019) |
| Internal conflict in last 5 years | 1.065 (0.068) |
1.065 (0.068) |
| Natural disasters | 0.991 (0.010) |
0.991 (0.010) |
| After 1989 | 4.799*** (1.010) |
4.884*** (1.042) |
| Constant | 0.091*** (0.044) |
0.092*** (0.044) |
| Random part (original coefficients) | ||
| Within-country variability (\(\sigma\)) | 0.491 (0.002) |
0.481 (0.001) |
| Within-year variability (\(\sigma\)) | 0.504 (0.002) |
0.512 (0.002) |
| Residual random error (\(\sigma\)) | 1.327 (0.000) |
1.327 (0.000) |
| Model details | ||
| Observations | 3,922 | 3,922 |
| Log likelihood (mean) | -6862.09 | -6861.22 |
| Imputed datasets (m) | 10 | 10 |
Neutral regulations and NGOs (H3)
table.robust.neutral.regs.h3 <- mods.robust.neutral.regs.melded.h3 %>%
stargazer.fake(exponentiate = TRUE) %>%
cat()| (1) | (2) | (3) | (4) | |
|---|---|---|---|---|
| Fixed part (odds ratios) | ||||
| Registration requirement | 1.178 (0.149) |
0.724** (0.103) |
||
| Funding disclosure requirement | 1.071 (0.129) |
1.005 (0.137) |
||
| Polity IV (0–10)within | 0.879** (0.049) |
0.878** (0.049) |
1.047 (0.063) |
1.045 (0.063) |
| Polity IV (0–10)between | 0.999 (0.029) |
0.994 (0.028) |
0.964 (0.032) |
0.977 (0.032) |
| GDP per capita (log)within | 2.009*** (0.525) |
2.004*** (0.529) |
0.302*** (0.077) |
0.280*** (0.072) |
| GDP per capita (log)between | 1.037 (0.074) |
1.048 (0.074) |
0.726*** (0.060) |
0.707*** (0.059) |
| Trade as % of GDPwithin | 1.000 (0.003) |
1.000 (0.003) |
0.997 (0.003) |
0.997 (0.003) |
| Trade as % of GDPbetween | 0.995*** (0.002) |
0.995*** (0.002) |
1.000 (0.002) |
0.999 (0.002) |
| Corruptionwithin | 1.200** (0.091) |
1.200** (0.091) |
1.140 (0.095) |
1.133 (0.094) |
| Corruptionbetween | 1.142*** (0.045) |
1.142*** (0.045) |
1.290*** (0.059) |
1.292*** (0.059) |
| Proportion of aid to domestic NGOs in present year (logit) | 1.389*** (0.031) |
1.391*** (0.031) |
||
| Proportion of aid to foreign NGOs in present year (logit) | 1.386*** (0.028) |
1.386*** (0.028) |
||
| Internal conflict in last 5 years | 1.228 (0.165) |
1.215 (0.163) |
1.151 (0.173) |
1.183 (0.178) |
| Natural disasters | 0.991 (0.015) |
0.990 (0.015) |
1.035** (0.018) |
1.035** (0.018) |
| Constant | 0.022*** (0.017) |
0.022*** (0.017) |
0.712 (0.624) |
0.685 (0.605) |
| Random part (original coefficients) | ||||
| Within-country variability (\(\sigma\)) | 0.711 (0.002) |
0.712 (0.002) |
0.844 (0.001) |
0.850 (0.001) |
| Within-year variability (\(\sigma\)) | 0.169 (0.002) |
0.173 (0.002) |
0.093 (0.006) |
0.090 (0.004) |
| Residual random error (\(\sigma\)) | 1.551 (0.001) |
1.552 (0.001) |
1.700 (0.002) |
1.702 (0.002) |
| Model details | ||||
| Observations | 1,751 | 1,751 | 1,751 | 1,751 |
| Log likelihood (mean) | -3374.09 | -3374.81 | -3537.15 | -3539.75 |
| Imputed datasets (m) | 5 | 5 | 5 | 5 |
Longer lags: H1
Looking at aid 2 years and 5 years after the change in anti-NGO legislation shows similar trends to 1 year after.
mods.h1.after_2.raw <- df.country.aid.demean.after_2.impute %>%
nest(-m) %>%
mutate(mod.h1.barriers.total = data %>%
future_map(mod.h1.barriers.total, "total.oda_log_next_year"),
mod.h1.type.total = data %>%
future_map(mod.h1.type.total, "total.oda_log_next_year"),
mod.h1.csre = data %>%
future_map(mod.h1.csre, "total.oda_log_next_year"))
# Get model details and parameters
mods.h1.after_2 <- mods.h1.after_2.raw %>%
gather(model.name, model, -m, -data) %>%
mutate(glance = model %>% map(broom::glance),
tidy = model %>% map(broom::tidy, conf.int = TRUE))
# Meld the imputed models
mods.h1.after_2.melded <- mods.h1.after_2 %>%
filter(m != "original") %>%
group_by(model.name) %>%
nest() %>%
mutate(tidy.melded = data %>% map(meld.imputed.models))mods.h1.after_5.raw <- df.country.aid.demean.after_5.impute %>%
nest(-m) %>%
mutate(mod.h1.barriers.total = data %>%
future_map(mod.h1.barriers.total, "total.oda_log_next_year"),
mod.h1.type.total = data %>%
future_map(mod.h1.type.total, "total.oda_log_next_year"),
mod.h1.csre = data %>%
future_map(mod.h1.csre, "total.oda_log_next_year"))
# Get model details and parameters
mods.h1.after_5 <- mods.h1.after_5.raw %>%
gather(model.name, model, -m, -data) %>%
mutate(glance = model %>% map(broom::glance),
tidy = model %>% map(broom::tidy, conf.int = TRUE))
# Meld the imputed models
mods.h1.after_5.melded <- mods.h1.after_5 %>%
filter(m != "original") %>%
group_by(model.name) %>%
nest() %>%
mutate(tidy.melded = data %>% map(meld.imputed.models))Effect on ODA after 2 years
| (1) | (2) | (3) | |
|---|---|---|---|
| Fixed part | |||
| Total legal barrierswithin | -0.069 (0.057) |
||
| Total legal barriersbetween | -0.052 (0.039) |
||
| Barriers to advocacywithin | -0.444* (0.257) |
||
| Barriers to advocacybetween | -0.088 (0.163) |
||
| Barriers to entrywithin | 0.070 (0.128) |
||
| Barriers to entrybetween | 0.128* (0.074) |
||
| Barriers to fundingwithin | -0.029 (0.148) |
||
| Barriers to fundingbetween | -0.180** (0.073) |
||
| Civil society reg. env. (CSRE)within | -0.020 (0.043) |
||
| Civil society reg. env. (CSRE)between | 0.058 (0.037) |
||
| Polity IV (0–10)within | -0.060** (0.029) |
-0.063** (0.029) |
-0.042 (0.040) |
| Polity IV (0–10)between | 0.009 (0.021) |
0.004 (0.021) |
-0.021 (0.033) |
| GDP per capita (log)within | -0.461** (0.189) |
-0.471** (0.189) |
-0.470** (0.189) |
| GDP per capita (log)between | -0.177*** (0.041) |
-0.172*** (0.041) |
-0.177*** (0.041) |
| Trade as % of GDPwithin | -0.004 (0.002) |
-0.003 (0.002) |
-0.003 (0.002) |
| Trade as % of GDPbetween | -0.002 (0.001) |
-0.002 (0.001) |
-0.002 (0.001) |
| Corruptionwithin | 0.054 (0.047) |
0.056 (0.047) |
0.054 (0.047) |
| Corruptionbetween | 0.046* (0.023) |
0.044* (0.023) |
0.049** (0.023) |
| Total aid in present year (log) | 0.865*** (0.007) |
0.861*** (0.007) |
0.865*** (0.007) |
| Internal conflict in last 5 years | 0.083 (0.105) |
0.075 (0.106) |
0.119 (0.105) |
| Natural disasters | 0.037** (0.015) |
0.036** (0.015) |
0.035** (0.015) |
| After 1989 | 0.590*** (0.151) |
0.618*** (0.150) |
0.571*** (0.156) |
| Constant | 3.225*** (0.458) |
3.109*** (0.460) |
3.204*** (0.457) |
| Random part | |||
| Within-country variability (\(\sigma\)) | 0.000 (0.000) |
0.000 (0.000) |
0.000 (0.000) |
| Within-year variability (\(\sigma\)) | 0.252 (0.007) |
0.246 (0.007) |
0.265 (0.007) |
| Residual random error (\(\sigma\)) | 2.730 (0.001) |
2.727 (0.001) |
2.729 (0.001) |
| Model details | |||
| Observations | 4,340 | 4,340 | 4,340 |
| Log likelihood (mean) | -10562.13 | -10559.29 | -10562.71 |
| Imputed datasets (m) | 5 | 5 | 5 |
Effect on ODA after 5 years
| (1) | (2) | (3) | |
|---|---|---|---|
| Fixed part | |||
| Total legal barrierswithin | -0.113* (0.064) |
||
| Total legal barriersbetween | -0.055 (0.039) |
||
| Barriers to advocacywithin | -0.313 (0.291) |
||
| Barriers to advocacybetween | -0.025 (0.169) |
||
| Barriers to entrywithin | -0.047 (0.138) |
||
| Barriers to entrybetween | 0.139* (0.076) |
||
| Barriers to fundingwithin | -0.091 (0.166) |
||
| Barriers to fundingbetween | -0.213*** (0.075) |
||
| Civil society reg. env. (CSRE)within | -0.031 (0.044) |
||
| Civil society reg. env. (CSRE)between | 0.040 (0.036) |
||
| Polity IV (0–10)within | -0.054* (0.029) |
-0.056* (0.029) |
-0.029 (0.041) |
| Polity IV (0–10)between | 0.005 (0.020) |
0.002 (0.021) |
-0.011 (0.032) |
| GDP per capita (log)within | -0.477** (0.191) |
-0.487** (0.191) |
-0.502*** (0.190) |
| GDP per capita (log)between | -0.116*** (0.041) |
-0.111*** (0.041) |
-0.118*** (0.041) |
| Trade as % of GDPwithin | -0.002 (0.002) |
-0.002 (0.002) |
-0.002 (0.002) |
| Trade as % of GDPbetween | -0.003** (0.001) |
-0.003** (0.001) |
-0.002** (0.001) |
| Corruptionwithin | 0.025 (0.048) |
0.027 (0.048) |
0.026 (0.048) |
| Corruptionbetween | 0.028 (0.023) |
0.028 (0.023) |
0.031 (0.023) |
| Total aid in present year (log) | 0.861*** (0.007) |
0.856*** (0.008) |
0.861*** (0.007) |
| Internal conflict in last 5 years | 0.099 (0.105) |
0.099 (0.106) |
0.131 (0.106) |
| Natural disasters | 0.029* (0.015) |
0.027* (0.015) |
0.026* (0.015) |
| After 1989 | 0.727*** (0.116) |
0.752*** (0.115) |
0.707*** (0.122) |
| Constant | 3.025*** (0.446) |
2.884*** (0.448) |
2.965*** (0.447) |
| Random part | |||
| Within-country variability (\(\sigma\)) | 0.000 (0.000) |
0.000 (0.000) |
0.000 (0.000) |
| Within-year variability (\(\sigma\)) | 0.100 (0.004) |
0.090 (0.005) |
0.112 (0.003) |
| Residual random error (\(\sigma\)) | 2.628 (0.001) |
2.626 (0.001) |
2.629 (0.001) |
| Model details | |||
| Observations | 3,920 | 3,920 | 3,920 |
| Log likelihood (mean) | -9386.61 | -9384 | -9388.68 |
| Imputed datasets (m) | 5 | 5 | 5 |
Longer lags: H2
mods.h2.after_2.raw <- df.country.aid.demean.after_2.impute %>%
nest(-m) %>%
mutate(mod.h2.barriers.total = data %>%
future_map(mod.h2.barriers.total, "prop.contentious_logit_next_year"),
mod.h2.type.total = data %>%
future_map(mod.h2.type.total, "prop.contentious_logit_next_year"),
mod.h2.csre = data %>%
future_map(mod.h2.csre, "prop.contentious_logit_next_year"))
# Get model details and parameters
mods.h2.after_2 <- mods.h2.after_2.raw %>%
gather(model.name, model, -m, -data) %>%
mutate(glance = model %>% map(broom::glance),
tidy = model %>% map(broom::tidy, conf.int = TRUE))
# Meld the imputed models
mods.h2.after_2.melded <- mods.h2.after_2 %>%
filter(m != "original") %>%
group_by(model.name) %>%
nest() %>%
mutate(tidy.melded = data %>% map(meld.imputed.models))mods.h2.after_5.raw <- df.country.aid.demean.after_5.impute %>%
nest(-m) %>%
mutate(mod.h2.barriers.total = data %>%
future_map(mod.h2.barriers.total, "prop.contentious_logit_next_year"),
mod.h2.type.total = data %>%
future_map(mod.h2.type.total, "prop.contentious_logit_next_year"),
mod.h2.csre = data %>%
future_map(mod.h2.csre, "prop.contentious_logit_next_year"))
# Get model details and parameters
mods.h2.after_5 <- mods.h2.after_5.raw %>%
gather(model.name, model, -m, -data) %>%
mutate(glance = model %>% map(broom::glance),
tidy = model %>% map(broom::tidy, conf.int = TRUE))
# Meld the imputed models
mods.h2.after_5.melded <- mods.h2.after_5 %>%
filter(m != "original") %>%
group_by(model.name) %>%
nest() %>%
mutate(tidy.melded = data %>% map(meld.imputed.models))Effect on contentious aid after 2 years
| (1) | (2) | (3) | |
|---|---|---|---|
| Fixed part | |||
| Total legal barrierswithin | 0.041 (0.031) |
||
| Total legal barriersbetween | -0.017 (0.046) |
||
| Barriers to advocacywithin | -0.255* (0.133) |
||
| Barriers to advocacybetween | -0.076 (0.184) |
||
| Barriers to entrywithin | 0.099 (0.067) |
||
| Barriers to entrybetween | 0.086 (0.085) |
||
| Barriers to fundingwithin | 0.124 (0.075) |
||
| Barriers to fundingbetween | -0.098 (0.094) |
||
| Civil society reg. env. (CSRE)within | 0.077*** (0.024) |
||
| Civil society reg. env. (CSRE)between | 0.046 (0.043) |
||
| Polity IV (0–10)within | 0.031* (0.016) |
0.030* (0.016) |
-0.016 (0.022) |
| Polity IV (0–10)between | 0.085*** (0.024) |
0.082*** (0.024) |
0.056 (0.038) |
| GDP per capita (log)within | -0.026 (0.095) |
-0.031 (0.096) |
-0.004 (0.095) |
| GDP per capita (log)between | -0.360*** (0.047) |
-0.356*** (0.047) |
-0.360*** (0.047) |
| Trade as % of GDPwithin | -0.002 (0.001) |
-0.002 (0.001) |
-0.002* (0.001) |
| Trade as % of GDPbetween | 0.002 (0.001) |
0.002 (0.001) |
0.002* (0.001) |
| Corruptionwithin | 0.055** (0.027) |
0.056** (0.027) |
0.061** (0.027) |
| Corruptionbetween | 0.063** (0.027) |
0.062** (0.027) |
0.067** (0.027) |
| Proportion of contentious aid in present year (logit) | 0.244*** (0.015) |
0.241*** (0.015) |
0.239*** (0.015) |
| Internal conflict in last 5 years | 0.057 (0.066) |
0.048 (0.066) |
0.079 (0.066) |
| Natural disasters | -0.008 (0.011) |
-0.008 (0.011) |
-0.010 (0.011) |
| After 1989 | 1.520*** (0.209) |
1.533*** (0.210) |
1.456*** (0.210) |
| Constant | -2.315*** (0.502) |
-2.443*** (0.512) |
-2.245*** (0.495) |
| Random part | |||
| Within-country variability (\(\sigma\)) | 0.497 (0.002) |
0.500 (0.002) |
0.498 (0.002) |
| Within-year variability (\(\sigma\)) | 0.493 (0.002) |
0.496 (0.002) |
0.495 (0.002) |
| Residual random error (\(\sigma\)) | 1.336 (0.000) |
1.335 (0.000) |
1.334 (0.000) |
| Model details | |||
| Observations | 3,808 | 3,808 | 3,808 |
| Log likelihood (mean) | -6693.91 | -6694.1 | -6689.21 |
| Imputed datasets (m) | 5 | 5 | 5 |
Effect on contentious aid after 5 years
| (1) | (2) | (3) | |
|---|---|---|---|
| Fixed part | |||
| Total legal barrierswithin | 0.026 (0.036) |
||
| Total legal barriersbetween | -0.012 (0.046) |
||
| Barriers to advocacywithin | -0.330** (0.156) |
||
| Barriers to advocacybetween | -0.025 (0.192) |
||
| Barriers to entrywithin | 0.106 (0.076) |
||
| Barriers to entrybetween | 0.075 (0.088) |
||
| Barriers to fundingwithin | 0.116 (0.089) |
||
| Barriers to fundingbetween | -0.093 (0.097) |
||
| Civil society reg. env. (CSRE)within | 0.080*** (0.025) |
||
| Civil society reg. env. (CSRE)between | 0.036 (0.043) |
||
| Polity IV (0–10)within | 0.028 (0.017) |
0.026 (0.017) |
-0.020 (0.023) |
| Polity IV (0–10)between | 0.088*** (0.024) |
0.087*** (0.024) |
0.065* (0.037) |
| GDP per capita (log)within | -0.062 (0.107) |
-0.067 (0.107) |
-0.046 (0.106) |
| GDP per capita (log)between | -0.370*** (0.047) |
-0.367*** (0.048) |
-0.371*** (0.047) |
| Trade as % of GDPwithin | -0.001 (0.001) |
-0.001 (0.001) |
-0.002 (0.001) |
| Trade as % of GDPbetween | 0.002 (0.001) |
0.002 (0.001) |
0.002* (0.001) |
| Corruptionwithin | 0.072** (0.030) |
0.073** (0.029) |
0.077*** (0.029) |
| Corruptionbetween | 0.058** (0.027) |
0.058** (0.027) |
0.061** (0.027) |
| Proportion of contentious aid in present year (logit) | 0.232*** (0.016) |
0.229*** (0.016) |
0.227*** (0.016) |
| Internal conflict in last 5 years | 0.089 (0.070) |
0.081 (0.070) |
0.108 (0.070) |
| Natural disasters | -0.008 (0.012) |
-0.008 (0.012) |
-0.010 (0.012) |
| After 1989 | 1.443*** (0.205) |
1.456*** (0.207) |
1.365*** (0.205) |
| Constant | -2.324*** (0.494) |
-2.442*** (0.507) |
-2.253*** (0.490) |
| Random part | |||
| Within-country variability (\(\sigma\)) | 0.497 (0.002) |
0.502 (0.002) |
0.499 (0.002) |
| Within-year variability (\(\sigma\)) | 0.474 (0.002) |
0.477 (0.002) |
0.470 (0.001) |
| Residual random error (\(\sigma\)) | 1.360 (0.000) |
1.359 (0.000) |
1.358 (0.000) |
| Model details | |||
| Observations | 3,446 | 3,446 | 3,446 |
| Log likelihood (mean) | -6122.67 | -6122.58 | -6117.85 |
| Imputed datasets (m) | 5 | 5 | 5 |