Results
Andrew Heiss and Suparna Chaudhry
Last run: 2020-10-01
library(tidyverse)
library(crackdownsphilanthropy)
library(rstan)
library(tidybayes)
library(broom)
library(ggstance)
library(ggdag)
library(ggraph)
library(patchwork)
library(pander)
library(scales)
library(janitor)
library(here)
source(here("analysis", "options.R"))
# Load data
results <- readRDS(here("data", "derived_data", "results_clean.rds"))
# qwraps2::lazyload_cache_dir("02_analysis_cache/html")Causal pathway
Our theory and hypotheses are laid out in the causal pathway below. Our outcomes (Y: % likely to donate and amount donated) “listen to” or respond to C (crackdown), which is our main treatment or exposure. Funding (F) and issue (I) serve as heuristics for donation and influence a government’s decision to crack down on NGOs, hence the dual arrows to C and Y.
theory_dag <- dagify(Y ~ I + C + F,
C ~ I + F,
outcome = "Y",
exposure = "C",
labels = c("Y" = "Outcome (Likelihood of donation & amount donated)",
"C" = "Anti-NGO legal crackdown",
"I" = "NGO issue area",
"F" = "NGO funding source")) %>%
tidy_dagitty(layout = "sugiyama")
plot_dag <- ggplot(theory_dag, aes(x = x, y = y, xend = xend, yend = yend)) +
geom_dag_point(size = 6) +
geom_dag_edges(start_cap = circle(4, "mm"),
end_cap = circle(4, "mm")) +
geom_dag_text(size = pts(6), family = "Roboto Condensed", fontface = "bold") +
geom_dag_label_repel(aes(label = label), size = pts(6), box.padding = 0.1,
direction = "x", seed = 12345,
family = "Roboto Condensed", fontface = "plain") +
labs(x = NULL) +
theme_ngos() +
theme(panel.grid = element_blank(),
axis.title = element_blank(),
axis.text = element_blank())
plot_dag %T>%
print() %T>%
ggsave(., filename = here("analysis", "output", "figures", "causal-path.pdf"),
width = 4.75, height = 2, units = "in", device = cairo_pdf) %>%
ggsave(., filename = here("analysis", "output", "figures", "causal-path.png"),
width = 4.75, height = 2, units = "in", type = "cairo", dpi = 300)
Overview of data
Balance of experimental conditions
results %>% count(crackdown, issue, funding) %>%
rename(Crackdown = crackdown, Issue = issue, Funding = funding) %>%
janitor::adorn_totals(., where = "row") %T>%
pandoc.table() %>%
pandoc.table.return(caption = "Balance of experimental conditions {#tbl:experimental-conditions}") %>%
cat(file = here("analysis", "output", "tables", "tbl-experimental-conditions.md"))| Crackdown | Issue | Funding | n |
|---|---|---|---|
| No crackdown | Human rights | Government | 68 |
| No crackdown | Human rights | Private | 64 |
| No crackdown | Humanitarian assistance | Government | 68 |
| No crackdown | Humanitarian assistance | Private | 65 |
| Crackdown | Human rights | Government | 65 |
| Crackdown | Human rights | Private | 65 |
| Crackdown | Humanitarian assistance | Government | 68 |
| Crackdown | Humanitarian assistance | Private | 68 |
| Total | - | - | 531 |
Descriptive statistics table
vars_to_summarize <- tribble(
~variable_name, ~clean_name,
"donate_likely", "Likelihood of donation",
"donate_likely_bin", "Likelihood of donation (binary)",
"amount_donate", "Amount hypothetically donated ($)",
"gender", "Gender",
"age", "Age",
"income", "Income",
"education", "Education",
"religiosity", "Frequency of attending religious services",
"ideology", "Political views",
"political_knowledge", "Frequency of following public affairs",
"give_charity", "Frequency of charitable donations",
"volunteer", "Volunteered in past 12 months",
"favor_humanitarian", "Prior favorability towards humanitarian NGOs",
"favor_humanitarian_bin", "Prior favorability towards humanitarian NGOs (binary)",
"favor_human_rights", "Prior favorability towards human rights NGOs",
"favor_human_rights_bin", "Prior favorability towards human rights NGOs (binary)",
"favor_development", "Prior favorability towards development NGOs",
"favor_development_bin", "Prior favorability towards development NGOs (binary)",
"check2", "Attention check 2"
)
results_summary_stats <- results %>%
select(one_of(vars_to_summarize$variable_name)) %>%
summarise_all(~list(.)) %>%
pivot_longer(everything(), names_to = "variable_name", values_to = "value") %>%
mutate(N = value %>% map_int(~ length(na.omit(.))),
summary = map2(.x = value, .y = variable_name, ~ md_summary_row(.x, .y))) %>%
left_join(vars_to_summarize, by = "variable_name") %>%
mutate(variable_name = factor(variable_name,
levels = vars_to_summarize$variable_name,
ordered = TRUE)) %>%
arrange(variable_name) %>%
select(-value, -variable_name) %>%
unnest(summary) %>%
select(Variable = clean_name, N, ` ` = spark, Details = summary)
results_summary_stats %>%
select(-N) %>%
pandoc.table.return(caption = "Descriptive statistics {#tbl:descriptive-stats}",
split.cell = 80, split.table = Inf) %T>%
cat(file = here("analysis", "output", "tables", "tbl-descriptive-stats.md")) %>%
cat()| Variable | Details | |
|---|---|---|
| Likelihood of donation |  |
Extremely unlikely (46; 8.66%) | Somewhat unlikely (110; 20.72%) | Neither likely nor unlikely (138; 25.99%) | Somewhat likely (192; 36.16%) | Extremely likely (45; 8.47%) |
| Likelihood of donation (binary) | 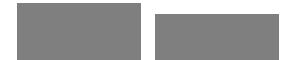 |
Not likely (294; 55%) | Likely (237; 45%) |
| Amount hypothetically donated ($) |  |
Median: 10 | Mean: 22.4 | Std. Dev.: 25.67 |
| Gender |  |
Female (291; 54.80%) | Male (237; 44.63%) | Other (1; 0.19%) | Prefer not to say (2; 0.38%) |
| Age | 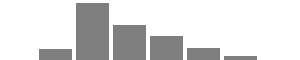 |
Under 18 (1; 0.19%) | 18 – 24 (43; 8.10%) | 25 – 34 (207; 38.98%) | 35 – 44 (129; 24.29%) | 45 – 54 (90; 16.95%) | 55 – 64 (44; 8.29%) | 65 – 74 (16; 3.01%) | 75 – 84 (1; 0.19%) |
| Income | 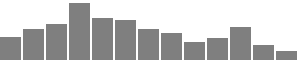 |
Less than $10,000 (32; 6.03%) | $10,000 – $19,999 (43; 8.10%) | $20,000 – $29,999 (50; 9.42%) | $30,000 – $39,999 (78; 14.69%) | $40,000 – $49,999 (58; 10.92%) | $50,000 – $59,999 (55; 10.36%) | $60,000 – $69,999 (43; 8.10%) | $70,000 – $79,999 (38; 7.16%) | $80,000 – $89,999 (25; 4.71%) | $90,000 – $99,999 (30; 5.65%) | $100,000 – $149,999 (45; 8.47%) | More than $150,000 (21; 3.95%) | Prefer not to say (13; 2.45%) |
| Education | 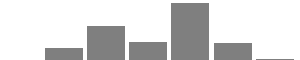 |
Less than high school (2; 0.38%) | High school graduate (47; 8.85%) | Some college (128; 24.11%) | 2 year degree (68; 12.81%) | 4 year degree (212; 39.92%) | Graduate or professional degree (66; 12.43%) | Doctorate (8; 1.51%) |
| Frequency of attending religious services | 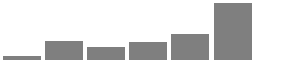 |
More than once a week (19; 3.58%) | Once a week (74; 13.94%) | Once or twice a month (50; 9.42%) | A few times a year (71; 13.37%) | Seldom (98; 18.46%) | Never (215; 40.49%) | Don’t know (4; 0.75%) |
| Political views | 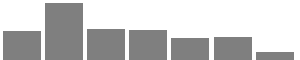 |
Strong liberal (76; 14.31%) | Liberal (150; 28.25%) | Independent, leaning liberal (82; 15.44%) | Independent (80; 15.07%) | Independent, leaning conservative (60; 11.30%) | Conservative (61; 11.49%) | Very conservative (22; 4.14%) |
| Frequency of following public affairs | 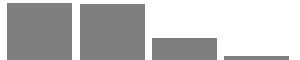 |
Most of the time (217; 40.87%) | Some of the time (213; 40.11%) | Only now and then (84; 15.82%) | Hardly at all (17; 3.20%) |
| Frequency of charitable donations |  |
Once a week (37; 6.97%) | Once a month (105; 19.77%) | Once every three months (105; 19.77%) | Once every six months (102; 19.21%) | Once a year (89; 16.76%) | Once every few years (56; 10.55%) | Never (37; 6.97%) |
| Volunteered in past 12 months |  |
No (288; 54.2%) | Yes (243; 45.8%) |
| Prior favorability towards humanitarian NGOs |  |
Very unfavorable (2; 0.38%) | Unfavorable (6; 1.13%) | Neutral (39; 7.34%) | Favorable (235; 44.26%) | Very favorable (249; 46.89%) |
| Prior favorability towards humanitarian NGOs (binary) |  |
Not favorable (47; 9%) | Favorable (484; 91%) |
| Prior favorability towards human rights NGOs |  |
Very unfavorable (5; 0.94%) | Unfavorable (12; 2.26%) | Neutral (61; 11.49%) | Favorable (226; 42.56%) | Very favorable (227; 42.75%) |
| Prior favorability towards human rights NGOs (binary) |  |
Not favorable (78; 15%) | Favorable (453; 85%) |
| Prior favorability towards development NGOs |  |
Very unfavorable (5; 0.94%) | Unfavorable (8; 1.51%) | Neutral (45; 8.47%) | Favorable (235; 44.26%) | Very favorable (238; 44.82%) |
| Prior favorability towards development NGOs (binary) |  |
Not favorable (58; 11%) | Favorable (473; 89%) |
| Attention check 2 |  |
Correct (531; 100%) |
Average likelihood and amount donated across conditions
conditions_summary <- bind_rows(group_by(results, crackdown, issue, funding) %>% nest(),
group_by(results, crackdown, issue) %>% nest(),
group_by(results, crackdown) %>% nest(),
results %>% nest(data = everything())) %>%
arrange(crackdown, issue, funding) %>%
mutate(summary = data %>%
map(~ summarize(., pct_likely = table(donate_likely_bin)[["Likely"]] /
length(donate_likely_bin),
mean_donation = mean(amount_donate, na.rm = TRUE),
sd_donation = sd(amount_donate, na.rm = TRUE),
N = nrow(.)))) %>%
unnest(summary) %>% select(-data) %>% ungroup()
conditions_summary_clean <- conditions_summary %>%
mutate(funding = ifelse(is.na(funding) & !is.na(issue) , "*Total*", as.character(funding)),
issue = ifelse(is.na(issue) & !is.na(crackdown), "*Total*", as.character(issue)),
crackdown = ifelse(is.na(crackdown), "*Total*", as.character(crackdown))) %>%
group_by(crackdown) %>%
mutate(issue = replace(issue, duplicated(issue), NA)) %>%
ungroup() %>%
mutate(crackdown = replace(crackdown, duplicated(crackdown), NA)) %>%
mutate(pct_likely = percent(pct_likely)) %>%
rename(`Crackdown condition` = crackdown, `Issue condition` = issue,
`Funding condition` = funding, `% likely to donate` = pct_likely,
`Amount donated (mean)` = mean_donation, `Amount donated (sd)` = sd_donation)
conditions_summary_clean %T>%
pandoc.table() %>%
pandoc.table.return(caption = "Average likelihood and amount donated across experimental conditions {#tbl:avg-results}") %>%
cat(file = here("analysis", "output", "tables", "tbl-avg-results.md"))| Crackdown condition | Issue condition | Funding condition | % likely to donate | Amount donated (mean) | Amount donated (sd) | N |
|---|---|---|---|---|---|---|
| No crackdown | Human rights | Government | 47.06% | 22.4 | 24.8 | 68 |
| Private | 39.06% | 19.3 | 22.4 | 64 | ||
| Total | 43.18% | 20.9 | 23.6 | 132 | ||
| Humanitarian assistance | Government | 44.12% | 17.9 | 21.4 | 68 | |
| Private | 40.00% | 21.9 | 26.9 | 65 | ||
| Total | 42.11% | 19.9 | 24.2 | 133 | ||
| Total | 42.64% | 20.4 | 23.9 | 265 | ||
| Crackdown | Human rights | Government | 29.23% | 19.4 | 25.8 | 65 |
| Private | 58.46% | 28 | 26.4 | 65 | ||
| Total | 43.85% | 23.7 | 26.3 | 130 | ||
| Humanitarian assistance | Government | 51.47% | 30.4 | 32.7 | 68 | |
| Private | 47.06% | 19.8 | 21.5 | 68 | ||
| Total | 49.26% | 25.1 | 28.1 | 136 | ||
| Total | 46.62% | 24.4 | 27.2 | 266 | ||
| Total | 44.63% | 22.4 | 25.7 | 531 |
Visualize important variables
Likelihood of donation
donate_summary <- results %>%
count(donate_likely) %>%
mutate(perc = n / sum(n)) %>%
mutate(highlight = ifelse(donate_likely %in% c("Extremely likely", "Somewhat likely"), TRUE, FALSE))
plot_donate_summary <- ggplot(donate_summary, aes(x = n, y = donate_likely,
fill = highlight)) +
geom_barh(stat = "identity") +
scale_x_continuous(sec.axis = sec_axis(~ . / sum(donate_summary$n),
labels = percent_format(accuracy = 1))) +
scale_fill_manual(values = ngo_cols("green", "blue", name = FALSE), guide = FALSE) +
labs(x = NULL, y = NULL) +
theme_ngos() +
theme(panel.grid.major.y = element_blank())
plot_donate_summary %T>%
print() %T>%
ggsave(., filename = here("analysis", "output", "figures", "donate_summary.pdf"),
width = 9, height = 4, units = "in", device = cairo_pdf) %>%
ggsave(., filename = here("analysis", "output", "figures", "donate_summary.png"),
width = 9, height = 4, units = "in", type = "cairo", dpi = 300)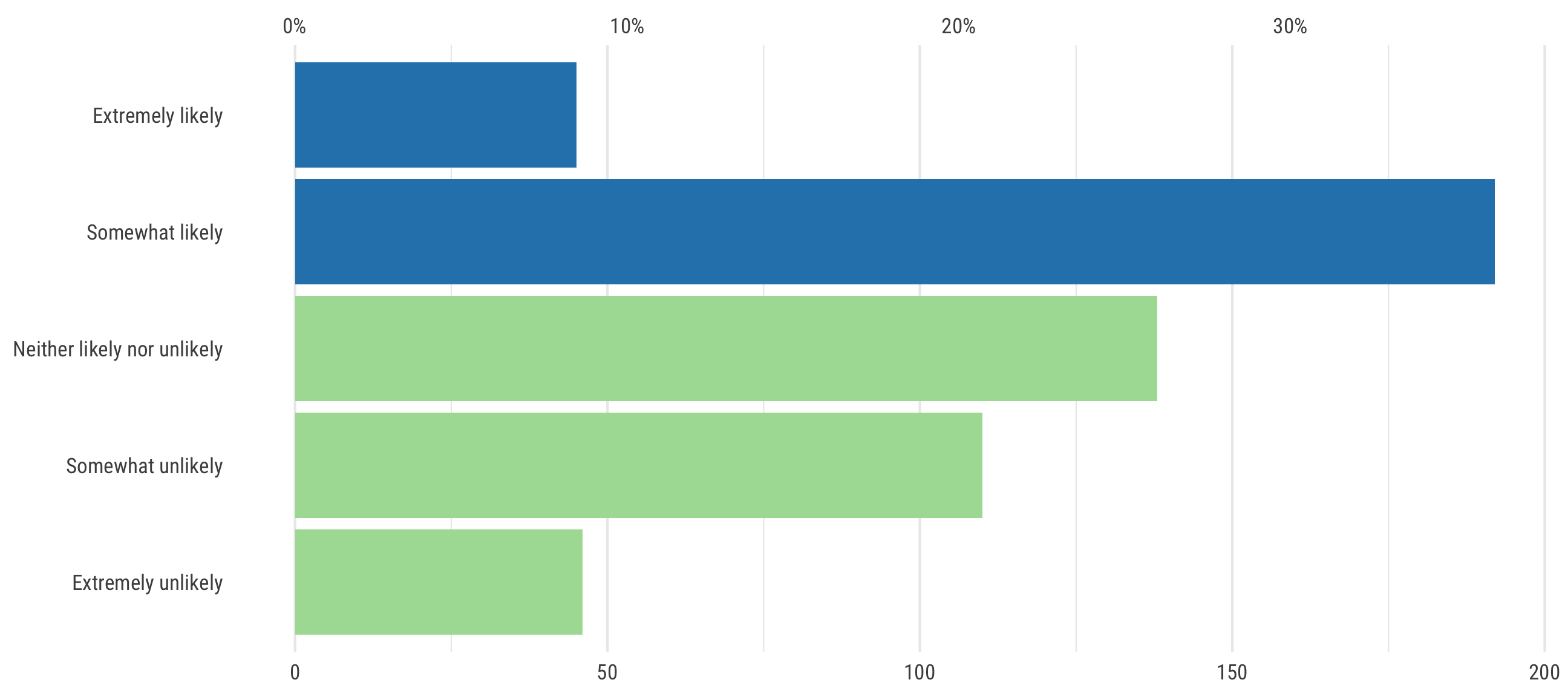
Amount donated
plot_amount_summary <- ggplot(results, aes(x = amount_donate)) +
geom_histogram(bins = 20, fill = ngo_cols("blue")) +
scale_x_continuous(labels = dollar) +
labs(x = NULL, y = NULL) +
theme_ngos() +
theme(panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank())
plot_amount_summary %T>%
print() %T>%
ggsave(., filename = here("analysis", "output", "figures", "amount_summary.pdf"),
width = 9, height = 2.75, units = "in", device = cairo_pdf) %>%
ggsave(., filename = here("analysis", "output", "figures", "amount_summary.png"),
width = 9, height = 2.75, units = "in", type = "cairo", dpi = 300)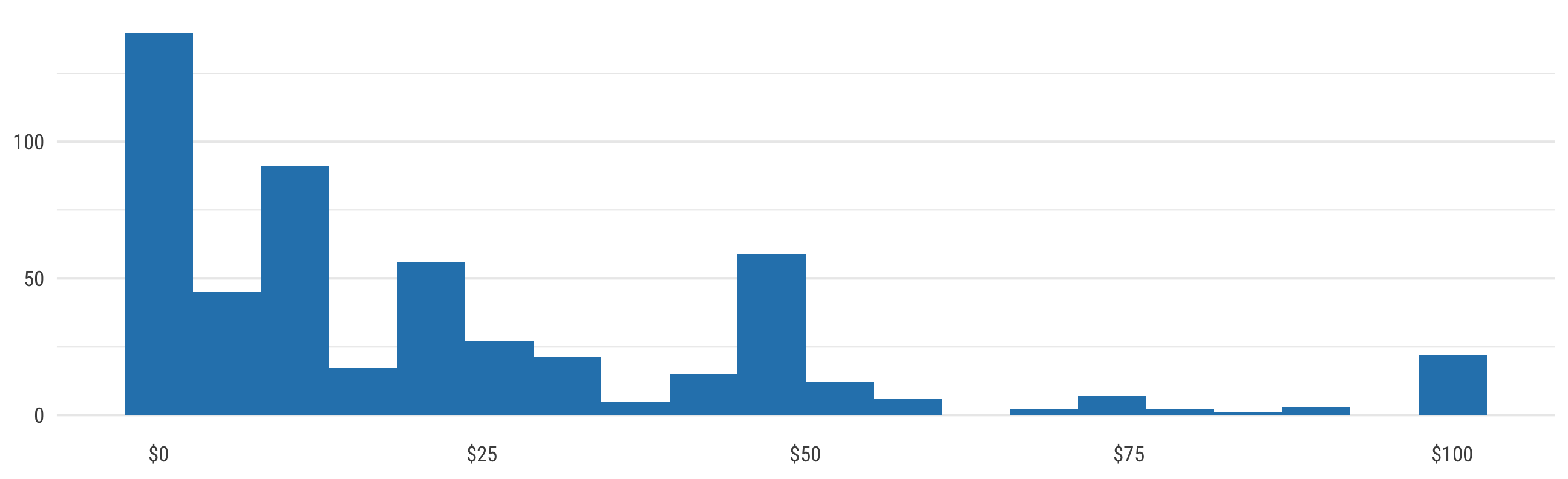
all_models <- tribble(
~title, ~df,
"Crackdown", results,
# Ha, cheat here by renaming the issue and funding columns to crackdown.
# All other tests are based on the crackdown column except these two, so
# rather than build all sorts of convoluted arguments and functions, we just
# rename these as issue and funding
"Issue", mutate(results, crackdown = issue),
"Funding", mutate(results, crackdown = funding),
# Create all the nested conditions
"Human rights | Crackdown", filter(results, issue == "Human rights"),
"Humanitarian assistance | Crackdown", filter(results, issue != "Human rights"),
"Government | Crackdown", filter(results, funding == "Government"),
"Private | Crackdown", filter(results, funding == "Private"),
"Human rights | Government | Crackdown", filter(results, issue == "Human rights", funding == "Government"),
"Human rights | Private | Crackdown", filter(results, issue == "Human rights", funding == "Private"),
"Humanitarian assistance | Government | Crackdown", filter(results, issue != "Human rights", funding == "Government"),
"Humanitarian assistance | Private | Crackdown", filter(results, issue != "Human rights", funding == "Private")
) Treatment effects: Likelihood of donation
This time around, we’re not using interactionful regression models to calculate all these differences in groups. Instead we use real live Stan code to estimate the differences in group means and proportions!
Priors and models
We estimate the proportion of people responding that they’d be likely to donate to the organization with a binomial distribution, with a prior \(\theta\) distribution of \(\text{Beta}(5, 5)\). We build the following model in Stan:
\[ \begin{aligned} n_{\text{group 1, group 2}} &\sim \text{Binomial}(n_{\text{total in group}}, \theta_{\text{group}}) &\text{[likelihood]}\\ \text{Difference} &= n_{\text{group 2}} - n_{\text{group 1}} &\text{[difference in proportions]} \\ n &: \text{Number likely to donate} \\ \\ \theta_{\text{group 1, group 2}} &\sim \text{Beta}(5, 5) &\text{[prior prob. of being likely to donate]} \end{aligned} \]
likely_theta <- ggplot(data = tibble(x = c(0, 1)), aes(x = x)) +
geom_area(stat = "function", fun = dbeta, args = list(shape1 = 5, shape2 = 5),
fill = "grey80", color = "black") +
labs(x = expression(Probability ~ of ~ being ~ likely ~ to ~ donate ~ (theta)), y = "Density") +
annotate(geom = "label", x = 0.5, y = 1, label = "Beta(5, 5)", size = pts(9)) +
theme_ngos(base_size = 9, density = TRUE)
likely_theta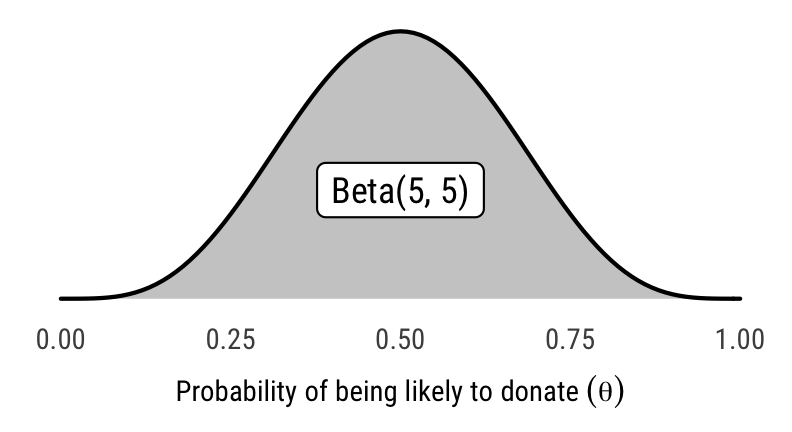
likely_theta %T>%
ggsave(., filename = here("analysis", "output", "figures", "prior-likely.pdf"),
width = 2.75, height = 1.5, units = "in", device = cairo_pdf) %>%
ggsave(., filename = here("analysis", "output", "figures", "prior-likely.png"),
width = 2.75, height = 1.5, units = "in", type = "cairo", dpi = 300)Differences
# This takes forever because of MCMC sampling, so this chunk is cached
# Sample from the compiled model
all_models_likely_run <- all_models %>%
# Simplify data for sending to Stan
mutate(stan_data_counts = df %>% map(~ {
df_counts <- .x %>%
count(crackdown, donate_likely_bin) %>%
group_by(crackdown) %>%
mutate(total = sum(n)) %>%
filter(donate_likely_bin == "Likely")
return(list(
n_total_1 = df_counts$total[1],
n_total_2 = df_counts$total[2],
n_likely_1 = df_counts$n[1],
n_likely_2 = df_counts$n[2]
))
})) %>%
# Run the actual model on the simplified data
mutate(model = stan_data_counts %>% map(~ {
donate_likely(n_total_1 = .x$n_total_1, n_total_2 = .x$n_total_2,
n_likely_1 = .x$n_likely_1, n_likely_2 = .x$n_likely_2,
control = list(max_treedepth = 15),
chains = CHAINS, iter = ITER, warmup = WARMUP, seed = BAYES_SEED)
}))
# Extract stuff
all_models_likely <- all_models_likely_run %>%
# Extract posterior chains
mutate(posterior_chains_long = map(model, ~ {
.x %>% gather_draws(theta_1, theta_2, theta_diff, pct_change)
})) %>%
mutate(posterior_chains_wide = map(model, ~ {
.x %>% spread_draws(theta_1, theta_2, theta_diff, pct_change)
})) %>%
# Get HDI medians in tidy form
mutate(tidy = posterior_chains_long %>% map(~ {
.x %>% median_hdci() %>% to_broom_names()
}))tidied_diffs_likely <- all_models_likely %>%
unnest(posterior_chains_long) %>%
filter(.variable == "theta_diff") %>%
mutate(category = case_when(
str_count(title, "\\|") == 0 ~ "Level 1",
str_count(title, "\\|") == 1 ~ "Level 2",
str_count(title, "\\|") == 2 ~ "Level 3"
)) %>%
mutate(title = str_remove(title, " \\| Crackdown"))
level1_likely <- tidied_diffs_likely %>%
filter(category == "Level 1") %>%
mutate(title = recode(title,
Crackdown = "Crackdown −\nNo crackdown",
Issue = "Humanitarian\nassistance −\nHuman rights",
Funding = "Private −\nGovernment\nfunding")) %>%
mutate(title = fct_inorder(title))
plot_diff_likely_a <- ggplot(level1_likely, aes(x = .value, y = fct_rev(title), fill = title)) +
stat_halfeye(.width = c(0.8, 0.95)) +
geom_vline(xintercept = 0) +
scale_x_continuous(labels = percent_format(accuracy = 1)) +
scale_fill_manual(values = ngo_cols(c("blue", "red", "orange"), name = FALSE), guide = FALSE) +
labs(x = "Difference in donation likelihood", y = NULL, tag = "A") +
theme_ngos(base_size = 8) +
theme(panel.grid.major.y = element_blank())
level2_likely <- tidied_diffs_likely %>%
filter(category == "Level 2") %>%
mutate(condition = case_when(
title %in% c("Human rights", "Humanitarian assistance") ~ "Issue",
title %in% c("Government", "Private") ~ "Funding"
)) %>%
mutate(facet_title = case_when(
title %in% c("Human rights", "Humanitarian assistance") ~ paste(title, "issues"),
title %in% c("Government", "Private") ~ paste(title, "funding")
)) %>%
mutate(title = case_when(
title %in% c("Humanitarian assistance", "Private") ~ "",
TRUE ~ "Crackdown −\nNo crackdown")
)
plot_diff_likely_b <- ggplot(filter(level2_likely, condition == "Issue"),
aes(x = .value, y = fct_rev(title))) +
stat_halfeye(.width = c(0.8, 0.95), fill = ngo_cols("red", name = FALSE)) +
geom_vline(xintercept = 0) +
scale_x_continuous(labels = percent_format(accuracy = 1)) +
labs(x = NULL, y = NULL, tag = "B") +
facet_wrap(~ facet_title, scales = "free_y") +
theme_ngos(base_size = 8) +
theme(panel.grid.major.y = element_blank())
plot_diff_likely_c <- ggplot(filter(level2_likely, condition == "Funding"),
aes(x = .value, y = fct_rev(title))) +
stat_halfeye(.width = c(0.8, 0.95), fill = ngo_cols("orange", name = FALSE)) +
geom_vline(xintercept = 0) +
scale_x_continuous(labels = percent_format(accuracy = 1)) +
labs(x = "Difference in donation likelihood", y = NULL, tag = "C") +
facet_wrap(~ facet_title, scales = "free_y") +
theme_ngos(base_size = 8) +
theme(panel.grid.major.y = element_blank())
level3_likely <- tidied_diffs_likely %>%
filter(category == "Level 3") %>%
separate(title, c("issue", "funding"), sep = " \\| ") %>%
mutate(issue = paste(issue, "issues"),
funding = paste(funding, "funding")) %>%
mutate(facet_title = paste0(issue, "\n", funding)) %>%
mutate(title = case_when(
funding == "Private funding" ~ "",
TRUE ~ "Crackdown −\nNo crackdown")
)
plot_diff_likely_d <- ggplot(level3_likely, aes(x = .value, y = fct_rev(title))) +
stat_halfeye(.width = c(0.8, 0.95), fill = ngo_cols("green", name = FALSE)) +
geom_vline(xintercept = 0) +
scale_x_continuous(labels = percent_format(accuracy = 1)) +
labs(x = "Difference in donation likelihood", y = NULL, tag = "D",
caption = "Point shows posterior median; thick black lines show 80% credible interval;\nthin black lines show 95% credible interval") +
facet_wrap(~ facet_title, scales = "free_y") +
theme_ngos(base_size = 8) +
theme(panel.grid.major.y = element_blank())
plot_diffs_likely_all <- plot_diff_likely_a /
(plot_diff_likely_b / plot_diff_likely_c) /
plot_diff_likely_d
plot_diffs_likely_all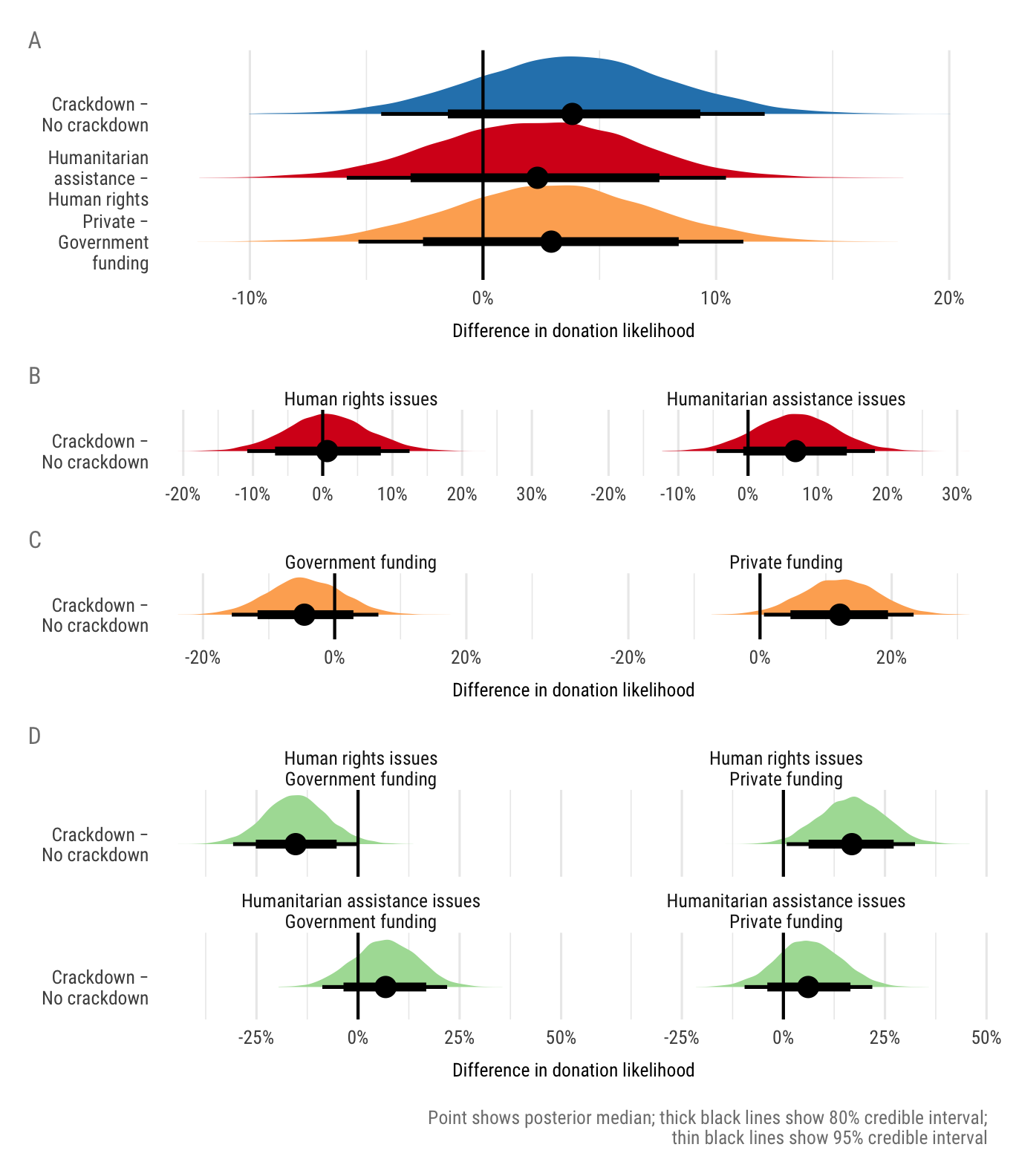
plot_diffs_likely_all %T>%
ggsave(., filename = here("analysis", "output", "figures", "likely-diffs.pdf"),
width = 4.75, height = 5.5, units = "in", device = cairo_pdf) %>%
ggsave(., filename = here("analysis", "output", "figures", "likely-diffs.png"),
width = 4.75, height = 5.5, units = "in", type = "cairo", dpi = 300)tbl_likely_tidy <- all_models_likely %>%
unnest(tidy) %>%
filter(term %in% c("theta_1", "theta_2", "theta_diff", "pct_change")) %>%
select(title, term, estimate) %>%
pivot_wider(names_from = term, values_from = estimate) %>%
mutate(category = case_when(
str_count(title, "\\|") == 0 ~ "Level 1",
str_count(title, "\\|") == 1 ~ "Level 2",
str_count(title, "\\|") == 2 ~ "Level 3"
))
tbl_likely_probs <- all_models_likely %>%
unnest(posterior_chains_long) %>%
filter(.variable == "theta_diff") %>%
group_by(title) %>%
summarize(p.greater0 = mean(.value > 0),
p.less0 = mean(.value < 0),
p.diff.not0 = ifelse(median(.value) > 0, p.greater0, p.less0)) %>%
ungroup()
# Save combined table for later use in manuscript
tbl_likely_tidy %>%
left_join(tbl_likely_probs, by = "title") %>%
saveRDS(here("data", "derived_data", "results_models_likely.rds"))
tbl_likely_1 <- tbl_likely_tidy %>%
left_join(tbl_likely_probs, by = "title") %>%
filter(category == "Level 1") %>%
mutate(title = recode(title,
Crackdown = "Crackdown − No crackdown",
Issue = "*Humanitarian assistance − Human rights*",
Funding = "*Private − Government funding*")) %>%
mutate_at(vars(theta_1, theta_2, theta_diff, pct_change),
list(~percent_format(accuracy = 0.1)(.))) %>%
mutate(p.diff.not0 = as.character(round(p.diff.not0, 2))) %>%
select(Frame = title, `% likely~Treatment~` = theta_2, `% likely~Control~` = theta_1,
`$\\Delta$` = theta_diff, `$\\%\\Delta$` = pct_change,
`$p(\\Delta \\neq 0)$` = p.diff.not0)tbl_likely_2 <- tbl_likely_tidy %>%
left_join(tbl_likely_probs, by = "title") %>%
filter(category == "Level 2") %>%
mutate(title_clean = str_remove(title, " \\| Crackdown")) %>%
mutate(title_clean = case_when(
title_clean %in% c("Human rights", "Humanitarian assistance") ~ paste(title_clean, "issues"),
title_clean %in% c("Government", "Private") ~ paste(title_clean, "funding")
)) %>%
mutate(title_clean = factor(title_clean,
levels = c("Human rights issues",
"Humanitarian assistance issues",
"Government funding", "Private funding"))) %>%
arrange(title_clean) %>%
mutate_at(vars(theta_1, theta_2, theta_diff, pct_change),
list(~percent_format(accuracy = 0.1)(.))) %>%
mutate(p.diff.not0 = as.character(round(p.diff.not0, 2))) %>%
mutate(title_clean = as.character(title_clean)) %>%
select(`H~2a~ and H~3a~` = title_clean,
`% likely~Crackdown~` = theta_2, `% likely~No\\ crackdown~` = theta_1,
`$\\Delta$` = theta_diff, `$\\%\\Delta$` = pct_change,
`$p(\\Delta \\neq 0)$` = p.diff.not0)tbl_likely_3 <- tbl_likely_tidy %>%
left_join(tbl_likely_probs, by = "title") %>%
filter(category == "Level 3") %>%
mutate(title_clean = str_remove(title, " \\| Crackdown")) %>%
separate(title_clean, c("Issue", "Funding"), sep = " \\| ") %>%
mutate(Issue = factor(Issue, levels = c("Human rights", "Humanitarian assistance")),
Funding = factor(Funding, levels = c("Government", "Private"))) %>%
arrange(Issue, Funding) %>%
mutate_at(vars(theta_1, theta_2, theta_diff, pct_change),
list(~percent_format(accuracy = 0.1)(.))) %>%
mutate(p.diff.not0 = as.character(round(p.diff.not0, 2))) %>%
mutate(Frame = paste0(Issue, " issues, ", Funding, " funding")) %>%
select(`H~2a~ and H~3a~ (nested)` = Frame,
`% likely~Crackdown~` = theta_2, `% likely~No\\ crackdown~` = theta_1,
`$\\Delta$` = theta_diff, `$\\%\\Delta$` = pct_change,
`$p(\\Delta \\neq 0)$` = p.diff.not0)tbl_likely_2_header <- enframe(colnames(tbl_likely_2)) %>%
mutate(value = (value)) %>%
pivot_wider(names_from = name, values_from = value) %>%
set_names(colnames(tbl_likely_1))
tbl_likely_3_header <- enframe(colnames(tbl_likely_3)) %>%
mutate(value = (value)) %>%
pivot_wider(names_from = name, values_from = value) %>%
set_names(colnames(tbl_likely_1))
bind_rows(tbl_likely_1,
tbl_likely_2_header,
set_names(tbl_likely_2, colnames(tbl_likely_1)),
tbl_likely_3_header,
set_names(tbl_likely_3, colnames(tbl_likely_1))) %>%
rename(`H~1a~` = Frame) %>%
pandoc.table.return(caption = 'Likelihood of donation and differences in proportions in "crackdown" (treatment) and "no crackdown" (control) conditions; values represent posterior medians {#tbl:likely-diffs}',
justify = "lccccc") %T>%
cat() %>%
cat(file = here("analysis", "output", "tables", "tbl-likely-diffs.md"))| H1a | % likelyTreatment | % likelyControl | \(\Delta\) | \(\%\Delta\) | \(p(\Delta \neq 0)\) |
|---|---|---|---|---|---|
| Crackdown − No crackdown | 46.7% | 42.9% | 3.8% | 8.9% | 0.82 |
| Humanitarian assistance − Human rights | 45.9% | 43.7% | 2.3% | 5.4% | 0.7 |
| Private − Government funding | 46.3% | 43.4% | 2.9% | 6.8% | 0.75 |
| H2a and H3a | % likelyCrackdown | % likelyNo crackdown | \(\Delta\) | \(\%\Delta\) | \(p(\Delta \neq 0)\) |
| Human rights issues | 44.3% | 43.6% | 0.6% | 1.5% | 0.54 |
| Humanitarian assistance issues | 49.4% | 42.5% | 6.8% | 15.9% | 0.88 |
| Government funding | 41.3% | 45.8% | -4.6% | -10.0% | 0.78 |
| Private funding | 52.4% | 40.3% | 12.1% | 30.2% | 0.98 |
| H2a and H3a (nested) | % likelyCrackdown | % likelyNo crackdown | \(\Delta\) | \(\%\Delta\) | \(p(\Delta \neq 0)\) |
| Human rights issues, Government funding | 32.0% | 47.4% | -15.4% | -32.5% | 0.97 |
| Human rights issues, Private funding | 57.4% | 40.4% | 16.9% | 41.5% | 0.98 |
| Humanitarian assistance issues, Government funding | 51.4% | 44.7% | 6.8% | 15.2% | 0.8 |
| Humanitarian assistance issues, Private funding | 47.5% | 41.2% | 6.1% | 14.8% | 0.78 |
Treatment effects: Amount donated
Priors and models
Following John Kruschke’s “Bayesian Estimation Supersedes the t-test (BEST)” procedure, we estimate means for each group with a t-distribution. We use the following priors for the distribution parameters:
\[ \begin{aligned} x_{\text{group 1, group 2}} &\sim \text{Student } t(\nu, \mu, \sigma) &\text{[likelihood]}\\ \text{Difference} &= x_{\text{group 2}} - x_{\text{group 1}} &\text{[difference in means]} \\ x &: \text{Mean amount donated} \\ \\ \nu &\sim \text{Exponential}(1 / 29) &\text{[prior normality]} \\ \mu_{\text{group 1, group 2}} &\sim \mathcal{N}(\bar{x}_{\text{group 1, group 2}}, 10) &\text{[prior donation mean per group]}\\ \sigma_{\text{group 1, group 2}} &\sim \text{Cauchy}(0, 1)&\text{[prior donation sd per group]} \end{aligned} \]
amount_nu <- ggplot(data = tibble(x = c(0, 200)), aes(x = x)) +
geom_area(stat = "function", fun = dexp, args = list(rate = 1/29),
fill = "grey80", color = "black") +
labs(x = expression(Normality ~ parameter ~ (nu)), y = "Density") +
annotate(geom = "label", x = 100, y = 0.009,
label = "Exponential(1/29)", size = pts(9)) +
theme_ngos(base_size = 9, density = TRUE)
amount_mu <- ggplot(data = tibble(x = c(0, 100)), aes(x = x)) +
geom_area(stat = "function", fun = dnorm, args = list(mean = 50, sd = 10),
fill = "grey80", color = "black") +
scale_x_continuous(breaks = c(seq(0, 100, 25)),
labels = c("−$50", "−$25", "Group average", "+$25", "+$50")) +
annotate(geom = "label", x = 50, y = 0.01, label = "N(bar(x), 10)",
parse = TRUE, size = pts(9)) +
labs(x = expression(Average ~ donated ~ (mu)), y = NULL) +
theme_ngos(base_size = 9, density = TRUE)
amount_sigma <- ggplot(data = tibble(x = c(0, 10)), aes(x = x)) +
geom_area(stat = "function", fun = dcauchy, args = list(location = 0, scale = 1),
fill = "grey80", color = "black") +
scale_x_continuous(labels = dollar) +
annotate(geom = "label", x = 5, y = 0.08, label = "Cauchy(0, 1)", size = pts(9)) +
labs(x = expression(SD ~ donated ~ (sigma)), y = NULL) +
theme_ngos(base_size = 9, density = TRUE)
amount_priors <- amount_nu + amount_mu + amount_sigma
amount_priors
amount_priors %T>%
ggsave(., filename = here("analysis", "output", "figures", "prior-amount.pdf"),
width = 8, height = 1.5, units = "in", device = cairo_pdf) %>%
ggsave(., filename = here("analysis", "output", "figures", "prior-amount.png"),
width = 8, height = 1.5, units = "in", type = "cairo", dpi = 300)Differences
# Sample from the compiled model
all_models_amount_run <- all_models %>%
# Simplify data for sending to Stan
mutate(stan_data = df %>% map(~ {
select(.x, amount = amount_donate, group = crackdown)
})) %>%
# Run the actual model on the simplified data
mutate(model = stan_data %>% map(~ {
amount_donated_best(df = .x, chains = CHAINS, iter = ITER,
warmup = WARMUP, seed = BAYES_SEED)
}))
# Extract stuff
all_models_amount <- all_models_amount_run %>%
# Extract posterior chains
mutate(posterior_chains_long = map2(model, stan_data, ~ {
.x %>%
recover_types(.y) %>%
gather_draws(mu[group], sigma[group], mu_diff, pct_change, cohen_d, cles, nu, log10nu)
})) %>%
mutate(posterior_chains_wide = map2(model, stan_data, ~ {
.x %>%
recover_types(.y) %>%
spread_draws(mu[group], sigma[group], mu_diff, pct_change, cohen_d, cles, nu, log10nu)
})) %>%
# Get HDI medians in tidy form
mutate(tidy = posterior_chains_long %>% map(~ {
.x %>% median_hdci() %>% to_broom_names()
}))all_models_amount <- all_models_amount %>%
# The `group` and `tidy` columns in each of these nested models contain
# ordered factors, but we can't combine them with unnest() directly because
# they have different levels (crackdown, issue, and funding), so we need to
# make them unordered factors before unnesting
mutate(posterior_chains_long = map(
posterior_chains_long, ~mutate(., group = factor(group, ordered = FALSE)))
) %>%
mutate(tidy = map(
tidy, ~mutate(., group = factor(group, ordered = FALSE)))
)
tidied_diffs_amount <- all_models_amount %>%
unnest(posterior_chains_long) %>%
filter(.variable == "mu_diff") %>%
mutate(category = case_when(
str_count(title, "\\|") == 0 ~ "Level 1",
str_count(title, "\\|") == 1 ~ "Level 2",
str_count(title, "\\|") == 2 ~ "Level 3"
)) %>%
mutate(title = str_remove(title, " \\| Crackdown"))
level1_amount <- tidied_diffs_amount %>%
filter(category == "Level 1") %>%
mutate(title = recode(title,
Crackdown = "Crackdown −\nNo crackdown",
Issue = "Humanitarian\nassistance −\nHuman rights",
Funding = "Private −\nGovernment\nfunding")) %>%
mutate(title = fct_inorder(title))
plot_diff_amount_a <- ggplot(level1_amount, aes(x = .value, y = fct_rev(title), fill = title)) +
geom_vline(xintercept = 0) +
stat_halfeye(.width = c(0.8, 0.95)) +
scale_x_continuous(labels = dollar) +
scale_fill_manual(values = ngo_cols(c("blue", "red", "orange"), name = FALSE), guide = FALSE) +
labs(x = "Difference in amount donated", y = NULL, tag = "A") +
theme_ngos(base_size = 8) +
theme(panel.grid.major.y = element_blank())
level2_amount <- tidied_diffs_amount %>%
filter(category == "Level 2") %>%
mutate(condition = case_when(
title %in% c("Human rights", "Humanitarian assistance") ~ "Issue",
title %in% c("Government", "Private") ~ "Funding"
)) %>%
mutate(facet_title = case_when(
title %in% c("Human rights", "Humanitarian assistance") ~ paste(title, "issues"),
title %in% c("Government", "Private") ~ paste(title, "funding")
)) %>%
mutate(title = case_when(
title %in% c("Humanitarian assistance", "Private") ~ "",
TRUE ~ "Crackdown −\nNo crackdown")
)
plot_diff_amount_b <- ggplot(filter(level2_amount, condition == "Issue"),
aes(x = .value, y = fct_rev(title))) +
stat_halfeye(.width = c(0.8, 0.95), fill = ngo_cols("red", name = FALSE)) +
geom_vline(xintercept = 0) +
scale_x_continuous(labels = dollar) +
labs(x = NULL, y = NULL, tag = "B") +
facet_wrap(~ facet_title, scales = "free_y") +
theme_ngos(base_size = 8) +
theme(panel.grid.major.y = element_blank())
plot_diff_amount_c <- ggplot(filter(level2_amount, condition == "Funding"),
aes(x = .value, y = fct_rev(title))) +
stat_halfeye(.width = c(0.8, 0.95), fill = ngo_cols("orange", name = FALSE)) +
geom_vline(xintercept = 0) +
scale_x_continuous(labels = dollar) +
labs(x = "Difference in amount donated", y = NULL, tag = "C") +
facet_wrap(~ facet_title, scales = "free_y") +
theme_ngos(base_size = 8) +
theme(panel.grid.major.y = element_blank())
level3_amount <- tidied_diffs_amount %>%
filter(category == "Level 3") %>%
separate(title, c("issue", "funding"), sep = " \\| ") %>%
mutate(issue = paste(issue, "issues"),
funding = paste(funding, "funding")) %>%
mutate(facet_title = paste0(issue, "\n", funding)) %>%
mutate(title = case_when(
funding == "Private funding" ~ "",
TRUE ~ "Crackdown −\nNo crackdown")
)
plot_diff_amount_d <- ggplot(level3_amount, aes(x = .value, y = fct_rev(title))) +
stat_halfeye(.width = c(0.8, 0.95), fill = ngo_cols("green", name = FALSE)) +
geom_vline(xintercept = 0) +
scale_x_continuous(labels = dollar) +
labs(x = "Difference in amount donated", y = NULL, tag = "D",
caption = "Point shows posterior median; thick black lines show 80% credible interval;\nthin black lines show 95% credible interval") +
facet_wrap(~ facet_title, scales = "free_y") +
theme_ngos(base_size = 8) +
theme(panel.grid.major.y = element_blank())
plot_diffs_amounts_all <- plot_diff_amount_a /
(plot_diff_amount_b / plot_diff_amount_c) /
plot_diff_amount_d
plot_diffs_amounts_all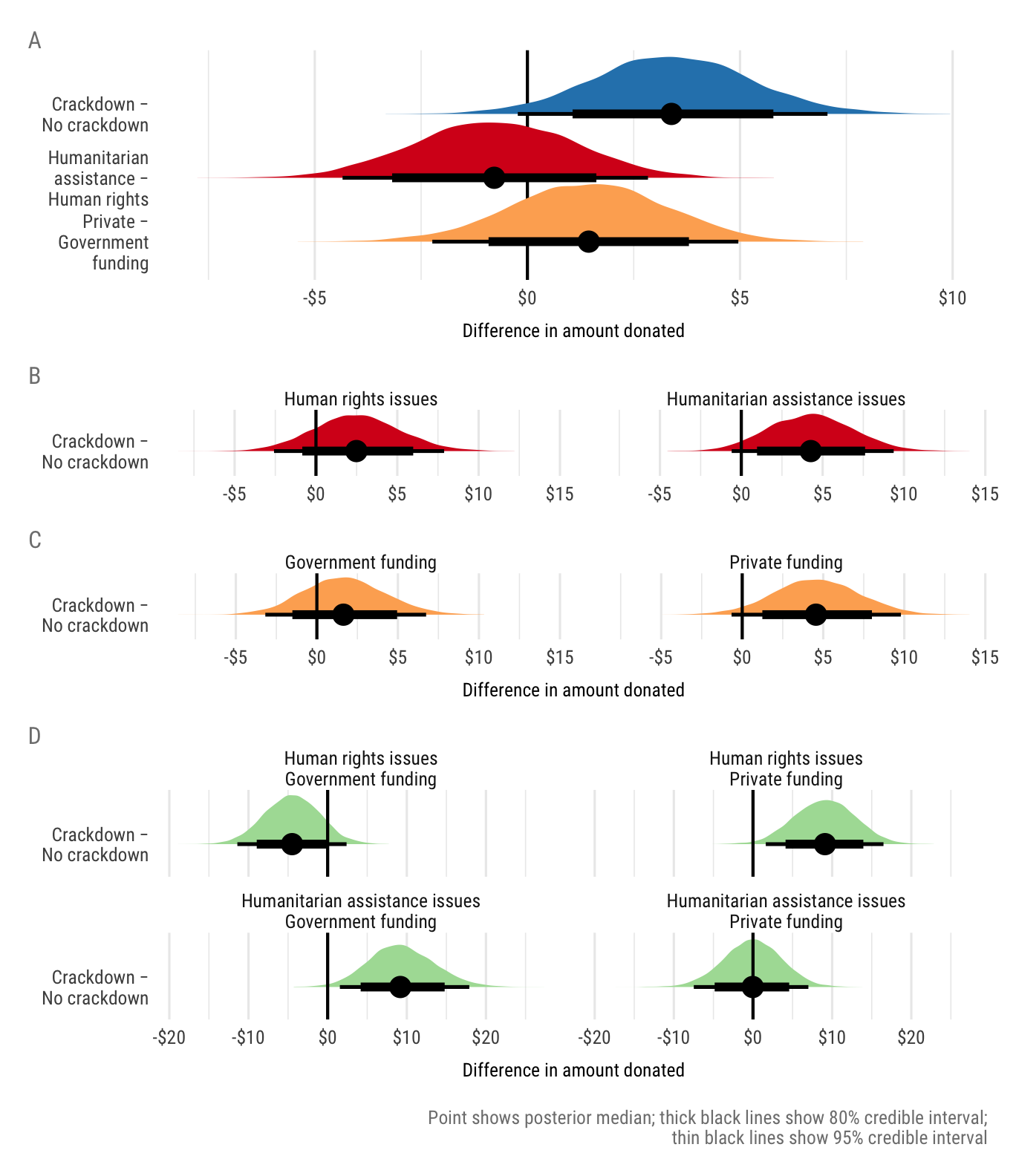
plot_diffs_amounts_all %T>%
ggsave(., filename = here("analysis", "output", "figures", "amount-diffs.pdf"),
width = 4.75, height = 5.5, units = "in", device = cairo_pdf) %>%
ggsave(., filename = here("analysis", "output", "figures", "amount-diffs.png"),
width = 4.75, height = 5.5, units = "in", type = "cairo", dpi = 300)tbl_amounts_tidy <- all_models_amount %>%
unnest(tidy) %>%
filter(term %in% c("mu", "mu_diff", "pct_change")) %>%
group_by(title) %>%
mutate(group_id = 1:n()) %>%
mutate(term = case_when(
term == "mu" ~ paste0(term, "_", group_id),
TRUE ~ term
)) %>%
select(title, term, estimate) %>%
pivot_wider(names_from = term, values_from = estimate) %>%
mutate(category = case_when(
str_count(title, "\\|") == 0 ~ "Level 1",
str_count(title, "\\|") == 1 ~ "Level 2",
str_count(title, "\\|") == 2 ~ "Level 3"
)) %>%
ungroup()
tbl_amounts_probs <- all_models_amount %>%
unnest(posterior_chains_long) %>%
filter(.variable == "mu_diff") %>%
group_by(title) %>%
summarize(p.greater0 = mean(.value > 0),
p.less0 = mean(.value < 0),
p.diff.not0 = ifelse(median(.value) > 0, p.greater0, p.less0)) %>%
ungroup()
# Save combined table for later use in manuscript
tbl_amounts_tidy %>%
left_join(tbl_amounts_probs, by = "title") %>%
saveRDS(here("data", "derived_data", "results_models_amount.rds"))
tbl_amount_1 <- tbl_amounts_tidy %>%
left_join(tbl_amounts_probs, by = "title") %>%
filter(category == "Level 1") %>%
mutate(title = recode(title,
Crackdown = "Crackdown − No crackdown",
Issue = "*Humanitarian assistance − Human rights*",
Funding = "*Private − Government funding*")) %>%
mutate_at(vars(mu_1, mu_2, mu_diff, p.diff.not0), list(~as.character(round(., 2)))) %>%
mutate(pct_change = percent_format(accuracy = 0.1)(pct_change)) %>%
select(`Frame` = title, `Amount~Treatment~` = mu_2, `Amount~Control~` = mu_1,
`$\\Delta$` = mu_diff, `$\\%\\Delta$` = pct_change,
`$p(\\Delta \\neq 0)$` = p.diff.not0)tbl_amount_2 <- tbl_amounts_tidy %>%
left_join(tbl_amounts_probs, by = "title") %>%
filter(category == "Level 2") %>%
mutate(title_clean = str_remove(title, " \\| Crackdown")) %>%
mutate(title_clean = case_when(
title_clean %in% c("Human rights", "Humanitarian assistance") ~ paste(title_clean, "issues"),
title_clean %in% c("Government", "Private") ~ paste(title_clean, "funding")
)) %>%
mutate(title_clean = factor(title_clean,
levels = c("Human rights issues",
"Humanitarian assistance issues",
"Government funding", "Private funding"))) %>%
arrange(title_clean) %>%
mutate_at(vars(mu_1, mu_2, mu_diff, p.diff.not0), list(~as.character(round(., 2)))) %>%
mutate(pct_change = percent_format(accuracy = 0.1)(pct_change)) %>%
mutate(title_clean = as.character(title_clean)) %>%
select(`H~2b~ and H~3b~` = title_clean, `Amount~Crackdown~` = mu_2, `Amount~No\\ crackdown~` = mu_1,
`$\\Delta$` = mu_diff, `$\\%\\Delta$` = pct_change,
`$p(\\Delta \\neq 0)$` = p.diff.not0)tbl_amount_3 <- tbl_amounts_tidy %>%
left_join(tbl_amounts_probs, by = "title") %>%
filter(category == "Level 3") %>%
mutate(title_clean = str_remove(title, " \\| Crackdown")) %>%
separate(title_clean, c("Issue", "Funding"), sep = " \\| ") %>%
mutate(Issue = factor(Issue, levels = c("Human rights", "Humanitarian assistance")),
Funding = factor(Funding, levels = c("Government", "Private"))) %>%
arrange(Issue, Funding) %>%
mutate(Frame = paste0(Issue, " issues, ", Funding, " funding")) %>%
mutate_at(vars(mu_1, mu_2, mu_diff, p.diff.not0), list(~as.character(round(., 2)))) %>%
mutate(pct_change = percent_format(accuracy = 0.1)(pct_change)) %>%
select(`H~2b~ and H~3b~ (nested)` = Frame,
`Amount~Crackdown~` = mu_2, `Amount~No\\ crackdown~` = mu_1,
`$\\Delta$` = mu_diff, `$\\%\\Delta$` = pct_change,
`$p(\\Delta \\neq 0)$` = p.diff.not0)tbl_amount_2_header <- enframe(colnames(tbl_amount_2)) %>%
mutate(value = (value)) %>%
pivot_wider(names_from = name, values_from = value) %>%
set_names(colnames(tbl_amount_1))
tbl_amount_3_header <- enframe(colnames(tbl_amount_3)) %>%
mutate(value = (value)) %>%
pivot_wider(names_from = name, values_from = value) %>%
set_names(colnames(tbl_amount_1))
bind_rows(tbl_amount_1,
tbl_amount_2_header,
set_names(tbl_amount_2, colnames(tbl_amount_1)),
tbl_amount_3_header,
set_names(tbl_amount_3, colnames(tbl_amount_1))) %>%
rename(`H~1b~` = Frame) %>%
pandoc.table.return(caption = 'Mean values and differences in means for amount donated in "crackdown" (treatment) and "no crackdown" (control) conditions; values represent posterior medians {#tbl:amount-diffs}',
justify = "lccccc") %T>%
cat() %>%
cat(file = here("analysis", "output", "tables", "tbl-amount-diffs.md"))| H1b | AmountTreatment | AmountControl | \(\Delta\) | \(\%\Delta\) | \(p(\Delta \neq 0)\) |
|---|---|---|---|---|---|
| Crackdown − No crackdown | 16.35 | 12.96 | 3.39 | 26.3% | 0.97 |
| Humanitarian assistance − Human rights | 14.01 | 14.84 | -0.78 | -5.3% | 0.66 |
| Private − Government funding | 15.11 | 13.65 | 1.44 | 10.6% | 0.78 |
| H2b and H3b | AmountCrackdown | AmountNo crackdown | \(\Delta\) | \(\%\Delta\) | \(p(\Delta \neq 0)\) |
| Human rights issues | 17.43 | 14.94 | 2.49 | 16.8% | 0.83 |
| Humanitarian assistance issues | 16.01 | 11.74 | 4.27 | 36.5% | 0.96 |
| Government funding | 13.87 | 12.26 | 1.64 | 13.5% | 0.74 |
| Private funding | 18.97 | 14.33 | 4.55 | 31.6% | 0.96 |
| H2b and H3b (nested) | AmountCrackdown | AmountNo crackdown | \(\Delta\) | \(\%\Delta\) | \(p(\Delta \neq 0)\) |
| Human rights issues, Government funding | 10.55 | 15.04 | -4.49 | -29.9% | 0.9 |
| Human rights issues, Private funding | 23.71 | 14.5 | 9.09 | 62.7% | 0.99 |
| Humanitarian assistance issues, Government funding | 21.42 | 11.97 | 9.18 | 76.4% | 0.99 |
| Humanitarian assistance issues, Private funding | 15.73 | 15.79 | -0.03 | -0.2% | 0.5 |
Effect size
# Effect size
# (μ₁ - μ₂) / sqrt( (σ₁² + σ₂²) / 2)
tidied_eff_size_amount <- all_models_amount %>%
unnest(posterior_chains_long) %>%
filter(.variable == "cohen_d") %>%
mutate(category = case_when(
str_count(title, "\\|") == 0 ~ "Level 1",
str_count(title, "\\|") == 1 ~ "Level 2",
str_count(title, "\\|") == 2 ~ "Level 3"
)) %>%
mutate(title = str_remove(title, " \\| Crackdown")) %>%
mutate(title = fct_inorder(title))
effect_sizes <- tribble(
~size, ~x_end,
"Small", 0.2,
"Medium", 0.5,
"Large", 0.8
) %>%
mutate(x_start = -x_end)
ggplot(tidied_eff_size_amount, aes(x = .value, y = fct_rev(title))) +
stat_halfeye(.width = c(0.8, 0.95)) +
geom_vline(xintercept = 0, size = 1) +
geom_vline(xintercept = c(0.2, -0.2), linetype = "dotted", size = 0.5) +
geom_vline(xintercept = c(0.5, -0.5), linetype = "dotted", size = 0.5) +
geom_vline(xintercept = c(0.5, -0.5), linetype = "dotted", size = 0.5) +
coord_cartesian(xlim = c(-1, 1)) +
labs(x = "Cohen's d (effect size)", y = NULL) +
theme_ngos()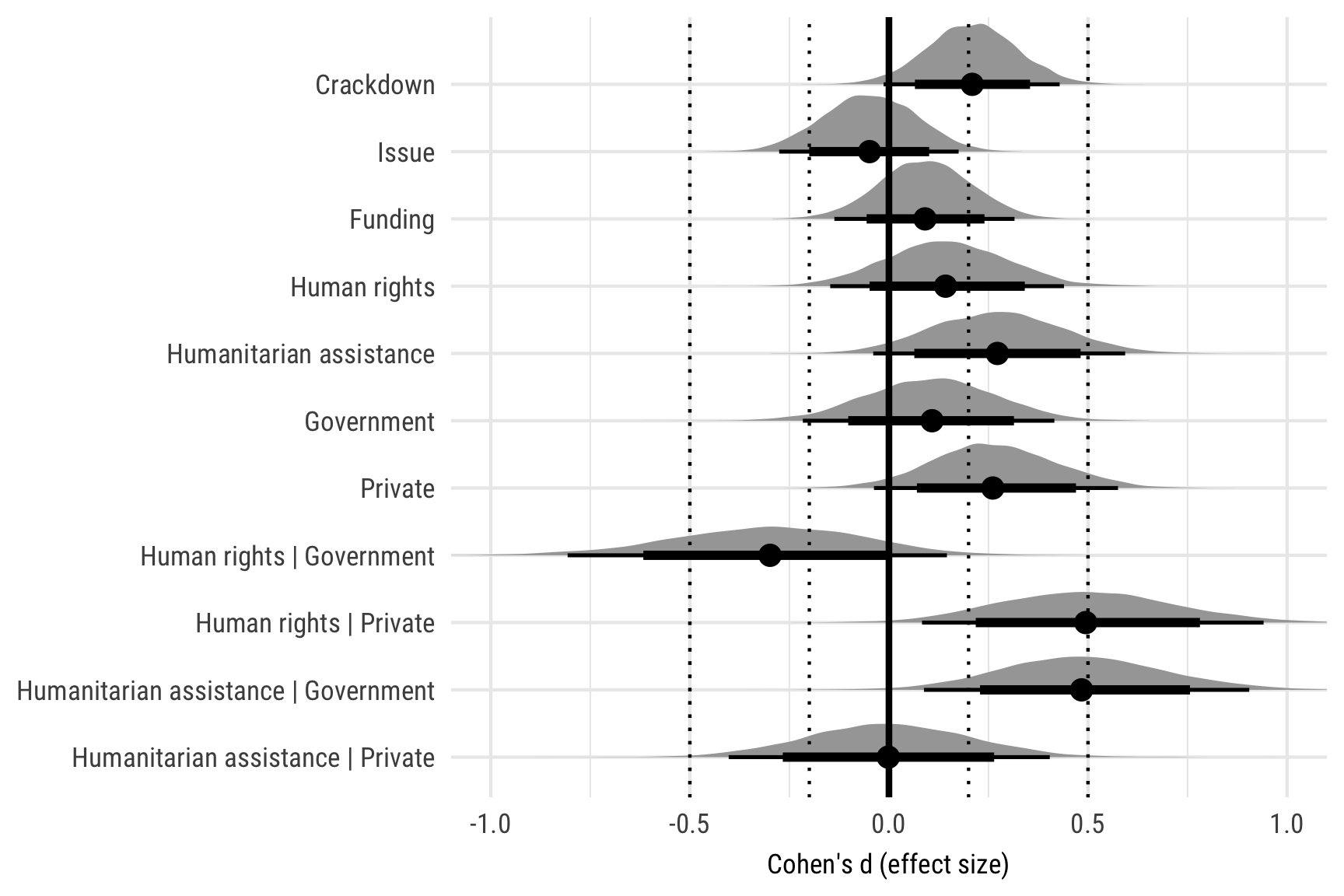
Original computing environment
## # http://dirk.eddelbuettel.com/blog/2017/11/27/#011_faster_package_installation_one
## VER=
## CCACHE=ccache
## CC=$(CCACHE) gcc$(VER)
## CXX=$(CCACHE) g++$(VER)
## CXX11=$(CCACHE) g++$(VER)
## CXX14=$(CCACHE) g++$(VER)
## FC=$(CCACHE) gfortran$(VER)
## F77=$(CCACHE) gfortran$(VER)
##
## CXX14FLAGS=-O3 -march=native -mtune=native -fPIC## ─ Session info ───────────────────────────────────────────────────────────────
## setting value
## version R version 4.0.2 (2020-06-22)
## os macOS Catalina 10.15.6
## system x86_64, darwin17.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz America/New_York
## date 2020-10-01
##
## ─ Packages ───────────────────────────────────────────────────────────────────
## package * version date lib source
## arrayhelpers 1.1-0 2020-02-04 [1] CRAN (R 4.0.0)
## assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.0.0)
## backports 1.1.9 2020-08-24 [1] CRAN (R 4.0.2)
## base64enc 0.1-3 2015-07-28 [1] CRAN (R 4.0.0)
## blob 1.2.1 2020-01-20 [1] CRAN (R 4.0.0)
## boot 1.3-25 2020-04-26 [1] CRAN (R 4.0.2)
## broom * 0.7.0 2020-07-09 [1] CRAN (R 4.0.2)
## callr 3.4.3 2020-03-28 [1] CRAN (R 4.0.0)
## cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.0.0)
## cli 2.0.2 2020-02-28 [1] CRAN (R 4.0.0)
## coda 0.19-3 2019-07-05 [1] CRAN (R 4.0.0)
## codetools 0.2-16 2018-12-24 [1] CRAN (R 4.0.2)
## colorspace 1.4-1 2019-03-18 [1] CRAN (R 4.0.0)
## crackdownsphilanthropy * 0.9 2020-10-01 [1] local
## crayon 1.3.4 2017-09-16 [1] CRAN (R 4.0.0)
## curl 4.3 2019-12-02 [1] CRAN (R 4.0.0)
## dagitty 0.3-0 2020-07-21 [1] CRAN (R 4.0.2)
## DBI 1.1.0 2019-12-15 [1] CRAN (R 4.0.0)
## dbplyr 1.4.4 2020-05-27 [1] CRAN (R 4.0.2)
## desc 1.2.0 2018-05-01 [1] CRAN (R 4.0.0)
## devtools 2.3.1 2020-07-21 [1] CRAN (R 4.0.2)
## digest 0.6.25 2020-02-23 [1] CRAN (R 4.0.0)
## distributional 0.2.0 2020-08-03 [1] CRAN (R 4.0.2)
## dplyr * 1.0.2 2020-08-18 [1] CRAN (R 4.0.2)
## ellipsis 0.3.1 2020-05-15 [1] CRAN (R 4.0.0)
## evaluate 0.14 2019-05-28 [1] CRAN (R 4.0.0)
## fansi 0.4.1 2020-01-08 [1] CRAN (R 4.0.0)
## farver 2.0.3 2020-01-16 [1] CRAN (R 4.0.0)
## forcats * 0.5.0 2020-03-01 [1] CRAN (R 4.0.0)
## fs 1.5.0 2020-07-31 [1] CRAN (R 4.0.2)
## generics 0.0.2 2018-11-29 [1] CRAN (R 4.0.0)
## ggdag * 0.2.2 2020-02-13 [1] CRAN (R 4.0.0)
## ggdist 2.2.0 2020-07-12 [1] CRAN (R 4.0.2)
## ggforce 0.3.2 2020-06-23 [1] CRAN (R 4.0.2)
## ggplot2 * 3.3.2 2020-06-19 [1] CRAN (R 4.0.2)
## ggraph * 2.0.3 2020-05-20 [1] CRAN (R 4.0.2)
## ggrepel 0.8.2 2020-03-08 [1] CRAN (R 4.0.0)
## ggstance * 0.3.4 2020-04-02 [1] CRAN (R 4.0.0)
## glue 1.4.2 2020-08-27 [1] CRAN (R 4.0.2)
## graphlayouts 0.7.0 2020-04-25 [1] CRAN (R 4.0.0)
## gridExtra 2.3 2017-09-09 [1] CRAN (R 4.0.0)
## gtable 0.3.0 2019-03-25 [1] CRAN (R 4.0.0)
## haven 2.3.1 2020-06-01 [1] CRAN (R 4.0.2)
## here * 0.1 2017-05-28 [1] CRAN (R 4.0.0)
## hms 0.5.3 2020-01-08 [1] CRAN (R 4.0.0)
## htmltools 0.5.0 2020-06-16 [1] CRAN (R 4.0.0)
## httr 1.4.2 2020-07-20 [1] CRAN (R 4.0.2)
## igraph 1.2.5 2020-03-19 [1] CRAN (R 4.0.0)
## inline 0.3.15 2018-05-18 [1] CRAN (R 4.0.0)
## janitor * 2.0.1 2020-04-12 [1] CRAN (R 4.0.0)
## jsonlite 1.7.0 2020-06-25 [1] CRAN (R 4.0.2)
## knitr 1.29 2020-06-23 [1] CRAN (R 4.0.2)
## labeling 0.3 2014-08-23 [1] CRAN (R 4.0.0)
## lattice 0.20-41 2020-04-02 [1] CRAN (R 4.0.2)
## lifecycle 0.2.0 2020-03-06 [1] CRAN (R 4.0.0)
## loo 2.3.1 2020-07-14 [1] CRAN (R 4.0.2)
## lubridate 1.7.9 2020-06-08 [1] CRAN (R 4.0.2)
## magrittr 1.5 2014-11-22 [1] CRAN (R 4.0.0)
## MASS 7.3-52 2020-08-18 [1] CRAN (R 4.0.2)
## matrixStats 0.56.0 2020-03-13 [1] CRAN (R 4.0.0)
## memoise 1.1.0 2017-04-21 [1] CRAN (R 4.0.0)
## modelr 0.1.8 2020-05-19 [1] CRAN (R 4.0.2)
## munsell 0.5.0 2018-06-12 [1] CRAN (R 4.0.0)
## pander * 0.6.3 2018-11-06 [1] CRAN (R 4.0.0)
## patchwork * 1.0.1 2020-06-22 [1] CRAN (R 4.0.2)
## pillar 1.4.6 2020-07-10 [1] CRAN (R 4.0.2)
## pkgbuild 1.1.0 2020-07-13 [1] CRAN (R 4.0.2)
## pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.0.0)
## pkgload 1.1.0 2020-05-29 [1] CRAN (R 4.0.2)
## plyr 1.8.6 2020-03-03 [1] CRAN (R 4.0.0)
## polyclip 1.10-0 2019-03-14 [1] CRAN (R 4.0.0)
## prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.0.0)
## processx 3.4.3 2020-07-05 [1] CRAN (R 4.0.0)
## ps 1.3.4 2020-08-11 [1] CRAN (R 4.0.2)
## purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.0.0)
## R6 2.4.1 2019-11-12 [1] CRAN (R 4.0.0)
## Rcpp 1.0.5 2020-07-06 [1] CRAN (R 4.0.2)
## RcppParallel 5.0.2 2020-06-24 [1] CRAN (R 4.0.2)
## readr * 1.3.1 2018-12-21 [1] CRAN (R 4.0.0)
## readxl 1.3.1 2019-03-13 [1] CRAN (R 4.0.0)
## remotes 2.2.0 2020-07-21 [1] CRAN (R 4.0.2)
## reprex 0.3.0 2019-05-16 [1] CRAN (R 4.0.0)
## rlang 0.4.7 2020-07-09 [1] CRAN (R 4.0.2)
## rmarkdown 2.3 2020-06-18 [1] CRAN (R 4.0.2)
## rprojroot 1.3-2 2018-01-03 [1] CRAN (R 4.0.0)
## rstan * 2.21.2 2020-07-27 [1] CRAN (R 4.0.2)
## rstudioapi 0.11 2020-02-07 [1] CRAN (R 4.0.0)
## rvest 0.3.6 2020-07-25 [1] CRAN (R 4.0.2)
## scales * 1.1.1 2020-05-11 [1] CRAN (R 4.0.0)
## sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 4.0.0)
## snakecase 0.11.0 2019-05-25 [1] CRAN (R 4.0.0)
## StanHeaders * 2.21.0-6 2020-08-16 [1] CRAN (R 4.0.2)
## stringi 1.4.6 2020-02-17 [1] CRAN (R 4.0.0)
## stringr * 1.4.0 2019-02-10 [1] CRAN (R 4.0.0)
## svUnit 1.0.3 2020-04-20 [1] CRAN (R 4.0.0)
## testthat 2.3.2 2020-03-02 [1] CRAN (R 4.0.0)
## tibble * 3.0.3 2020-07-10 [1] CRAN (R 4.0.2)
## tidybayes * 2.1.1 2020-06-19 [1] CRAN (R 4.0.2)
## tidygraph 1.2.0 2020-05-12 [1] CRAN (R 4.0.0)
## tidyr * 1.1.2 2020-08-27 [1] CRAN (R 4.0.2)
## tidyselect 1.1.0 2020-05-11 [1] CRAN (R 4.0.0)
## tidyverse * 1.3.0 2019-11-21 [1] CRAN (R 4.0.0)
## tweenr 1.0.1 2018-12-14 [1] CRAN (R 4.0.0)
## usethis 1.6.1 2020-04-29 [1] CRAN (R 4.0.0)
## V8 3.2.0 2020-06-19 [1] CRAN (R 4.0.2)
## vctrs 0.3.4 2020-08-29 [1] CRAN (R 4.0.2)
## viridis 0.5.1 2018-03-29 [1] CRAN (R 4.0.0)
## viridisLite 0.3.0 2018-02-01 [1] CRAN (R 4.0.0)
## withr 2.2.0 2020-04-20 [1] CRAN (R 4.0.0)
## xfun 0.16 2020-07-24 [1] CRAN (R 4.0.2)
## xml2 1.3.2 2020-04-23 [1] CRAN (R 4.0.0)
## yaml 2.2.1 2020-02-01 [1] CRAN (R 4.0.0)
##
## [1] /Library/Frameworks/R.framework/Versions/4.0/Resources/library